Resources
Beyond Numbers: Understanding Translation Quality Estimation Scores
21/12/2023

Learn how TAUS Quality Estimation (QE) scores are calculated, interpreted, and used to improve machine translation accuracy.
Author

Dace is a product and operations management professional with 15+ years of experience in the localization industry. Over the past 7 years, she has taken on various roles at TAUS ranging from account management to product and operations management. Since 2020 she is a member of the Executive Team and leads the strategic planning and business operations of a team of 20+ employees. She holds a Bachelor’s degree in Translation and Interpreting and a Master’s degree in Social and Cultural Anthropology.
Related Articles

 by David Koot
by David Koot09/01/2026
TAUS EPIC API's customizable Quality Estimation models can enhance translation workflows and meet specific needs without requiring in-house NLP expertise.


05/12/2025
Explore how TAUS EPIC API's Quality Estimation can revolutionize translation workflows, that offer scalable, domain-specific solutions for Language Service Providers without the need for in-house NLP experts.
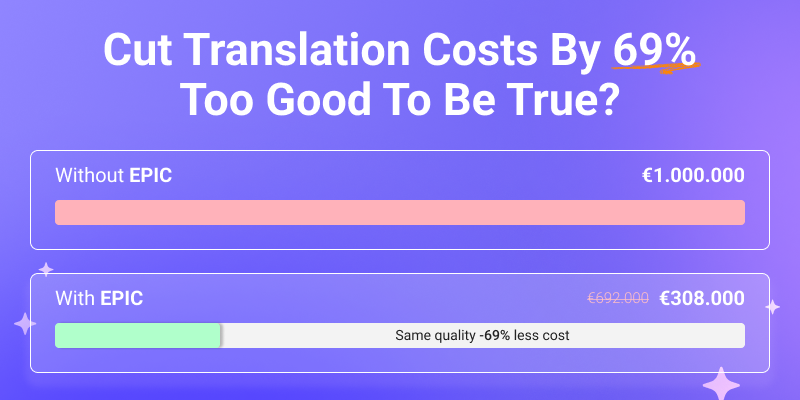

30/10/2025
See your translation ROI with Quality Estimation (QE) and Automatic Post-Editing (APE). Find out how EPIC can reduce post-editing costs by up to 70% while improving efficiency.