EPIC
Resources

While there are many ways to get clean data, at TAUS we distinguish ten different steps, five of which are mandatory to get clean and high-quality datasets. Whether you apply one (or all) of the last five steps, depends on your requirements, data purposes and the quality of the original dataset. Some of these steps are completely automatic (done through specific tools), while others are done with human supervision or completely manual (done by humans).
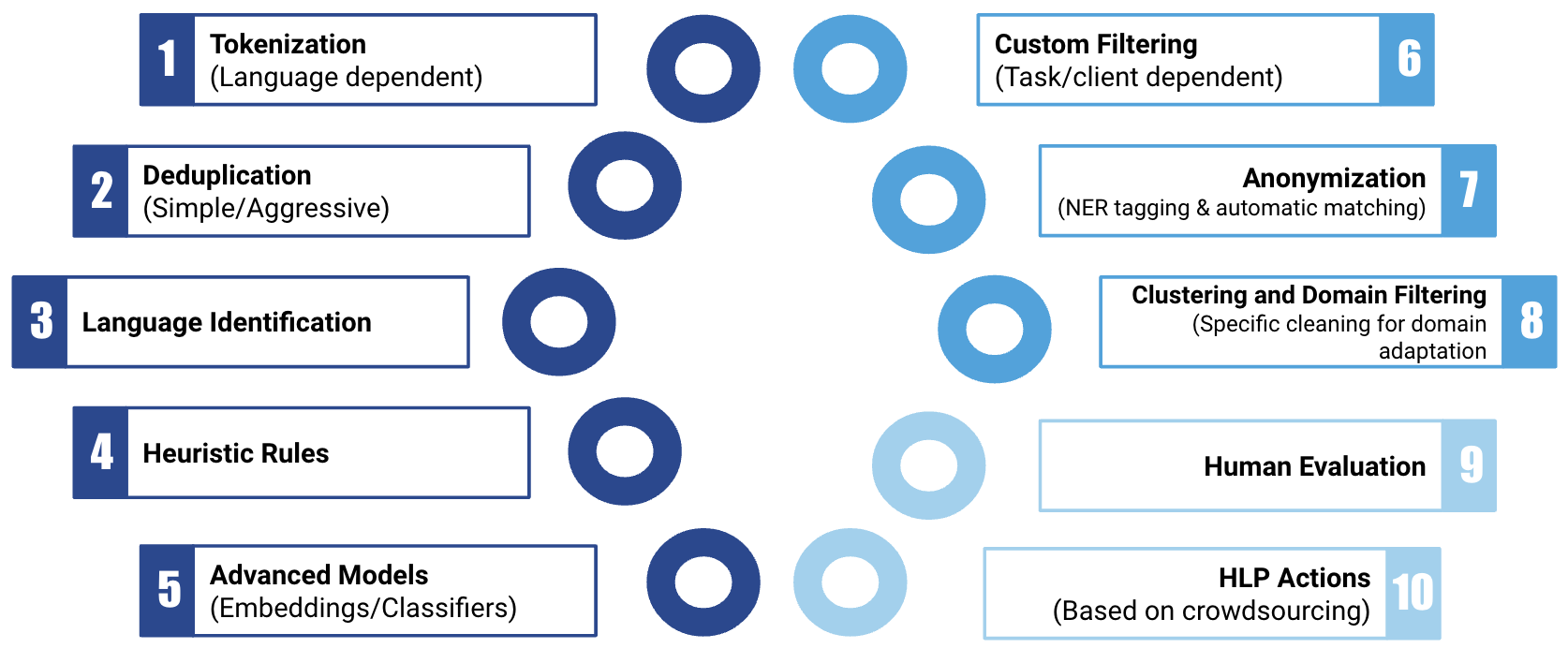
Tokenization is the process of separating a text into smaller units, called tokens. It is a language dependent task, because the boundaries between words are not the same in each language and script. In English, the spaces between words help us to easily define each word. However, not all languages have this common denominator. So to easily distinguish the individual words in a text, the process of tokenization is used.
There are many (free) tokenization models available on the web. A few examples are NLTK, Stanford Tokenizer, Moses (for European languages only), spaCy, Stanza NLP.
To be able to use a tokenization model, you need to have some basic programming knowledge. Furthermore, you need to do some research into the capabilities of the tokenization and compare these with your needs. Not all tokenization models are applicable to all languages. In order to use the tokenization tools and get good results, most likely a customization of the tool is needed, matching your language and domain.
Duplication is one of the main problems that are found in large translation memories. The reason for this is that there is a lot of repetition (use of the same sentences and word combinations) which is constantly being added to the translation memory file.
Why do we want to remove duplicates from a dataset before we train an MT engine with it? It is important to understand that MT engine training is all about learning and understanding patterns. So when there is an overwhelming amount of the same segment in a dataset that is used to train the engine, the algorithm will give preference to this segment.
Deduplication (removing duplicate sentences) sounds very easy. However, in order to start with the deduplication of your text, you’ll need to consider a few things:
The process of deduplication is as follows:

In other words: every token in a text needs to get a unique identifier or ‘hash’ (usually a number) so that it can be recognized when you apply the hash matching algorithm. When handling datasets with millions of segments, this automatic process can save a lot of time.
Sometimes, when you have a dataset that is delivered as a certain language pair you still find segments in the source or target that are a different language. How do you identify the languages in a dataset? There are a number of tools available that help with language identification. Two of the most widely used tools are Fasttext from Facebook AI Research labs (supports 176 languages) and CLD3 from Google (supports 107 languages).
It is important to note that when a dataset consists of short sentences, identifying the language becomes more difficult. Furthermore, language identification should only be used when the confidence of the prediction is high and multiple different libraries can be used to pick the right language. The reason for this is that not all tools have the same level of predictive accuracy for each language and not every language is identified correctly.
Once you’ve been able to identify the language(s), you can go ahead and remove sentences that are different from the language that is identified. A custom threshold can be used to allow a few words of different languages in the sentence. For example, loanwords and names.
A dataset can also contain other issues such as misalignment, length, punctuation or encoding issues. Eliminating these kinds of problems in data is done by using basic heuristic rules.
Heuristic rules are simple programming rules written to help identify instances in a text. Let’s look at a few examples.
Source = Target (Misalignment)
When either the source is copied to the target or the target is copied to the source, whether it’s the full sentence or half of it, we call it misalignment. Although this looks like harmless ‘noise’, research shows that having even only 5% of these issues in your dataset can easily ruin a translation model (when BLEU scores go down with 10 points or more). In some cases, having the source and target be the same is actually okay. Think about addresses or URLs. In order to identify these instances, language identification and Named Entity Recognition (NER tagging) come in handy.
Length-Based Rules
When text is translated from one language to another, the length of the source and target text is likely to be different. Some languages are more “wordy” (use more words to express the same) while others are more compact. The differences in length per language can be defined in a somewhat systematic way through a “length ratio”. If you identify the source and target language, and know the length ratio of this language pair, applying heuristic rules based on length can help you to easily spot noise in your dataset. In order to do this, it is important to tokenize your text first. Note that this rule can only be applied where the ratio of Source vs Target words is predictable.
Ratio of Numbers/Punctuations with content words
Sometimes you come across sentences with lots of numbers or punctuation, but with only a few actual words in it. These sentences are not interesting for MT models and it is best to remove these from your dataset before you train the engine. A heuristic rule to identify the ratio of numbers and punctuation with content words will help you to easily identify these sentences and remove them.
Correction of encodings issues
And lastly, you could find repeated encoding issues that follow a certain pattern. Custom heuristic rules, such as regular expressions, can also be written to fix these patterns of encoding issues.
There are also standard tools available that come in handy when fixing many well-known encoding issues. Examples are ftfy (fixes text for you), Bifixer.
If you’ve walked through the cleaning steps 1 through 4 and the translation is still not correct, you can continue with an advanced model like sentence embeddings. Sentence embedding is the process of transforming text into numbers and multidimensional vectors, so that computer algorithms are able to read them. A cleaning algorithm that relies on sentence embeddings to establish the levels of translational equivalence outputs a number between 0 and 1 for source and target sentences. The closer the result is to 1, the higher the similarity between the sentences. Sentence embeddings can also be used to assess the semantic relationship between two sentences, such as: similarity, contradiction, entailment, but also translational equivalence. To get a full understanding of sentence embeddings, please read our blog on Sentence Embeddings and their Applications.
The past five steps we discussed are all well-known cleaning techniques. However, sometimes a task requires specific customization, based on the client's needs. Customized cleaning can include:
Once you have a clear understanding of your needs, custom filtering and cleaning rules can be manually written by a language data cleaning expert.
An important part of the data cleaning process is anonymization. New rules formed under GDPR (in Europe) and similar laws in other parts of the world require businesses to handle Personally Identifiable Information (PII) carefully. Whether PIIs need to be anonymized depends on the context of the text.
For example, publicly shared information such as the name and address of a restaurant does not need to be anonymized. However, private information, such as the name and address of a medical patient do require anonymization.
There are available tools that recognize PIIs, but so far they are not able to distinguish between sensitive (private) and non-sensitive (publicly available) PII. This means that these tools identify a high number of false positives (i.e. PII that does not need to be anonymized).
To correctly identify which PIIs need anonymization and which do not, human supervision is needed. A combination of automatic tagging of PIIs using Named Entity Recognition (NER), custom rules and manual micro tasks will be able to solve this problem. The manual micro tasks can be done by either internal staff, external staff or through crowdsourcing. All they need is a given set of rules about sensitive and non-sensitive information for a particular task or scenario.
To further clean your dataset, clustering and domain filtering techniques can come into play.
Clustering is the task of grouping data points (in our case, a set of sentences) together that have similar characteristics, forming clusters. What these similarities are depends on the client’s needs. For example, you can isolate sentences with a particular grammatical structure or shared vocabulary.
Domain filtering is similar to clustering, however, the data points are now grouped together based on one specific similarity, namely their domain. For example, if a company is building an MT engine specifically for the pharmaceutical industry, it is important to train the model on a data set that contains sentences from that domain.
With Matching Data, an information retrieval algorithm developed by TAUS, you can identify sentences that are relevant to a particular domain from a large pool of sentences. With the new sentence embeddings technique, semantic-based filtering capabilities can be added on top of that. Combining these two techniques results in good-quality domain-specific datasets.
Using clustering and domain classification techniques, smaller domain-specific datasets can also be produced from a large translation memory, when the domains are not already known.
On top of all the automatic and supervised cleaning discussed in this section, human evaluation of datasets can also be done. Whatever type of human evaluation is needed depends of course on the project, the needs, goals and objectives of the project and the people involved in the project.
TAUS has developed a platform called the Human Language Project on which controlled crowd communities help with data-related micro-tasks, such as text and speech data creation, annotation, evaluation, post-editing and more. The data workers can also help with cleaning tasks. For example, with the automatic tagging of PIIs using the combination of Named-Entity Recognition (NER) and custom rules. Or by performing the task of anonymization given a set of rules about sensitive and non-sensitive information for a particular task or scenario.

Anne-Maj van der Meer is a marketing professional with over 10 years of experience in event organization and management. She has a BA in English Language and Culture from the University of Amsterdam and a specialization in Creative Writing from Harvard University. Before her position at TAUS, she was a teacher at primary schools in regular as well as special needs education. Anne-Maj started her career at TAUS in 2009 as the first TAUS employee where she became a jack of all trades, taking care of bookkeeping and accounting as well as creating and managing the website and customer services. For the past 5 years, she works in the capacity of Events Director, chief content editor and designer of publications. Anne-Maj has helped in the organization of more than 35 LocWorld conferences, where she takes care of the program for the TAUS track and hosts and moderates these sessions.