Resources
NLP-driven Word Clouds in Data Marketplace
03/01/2022
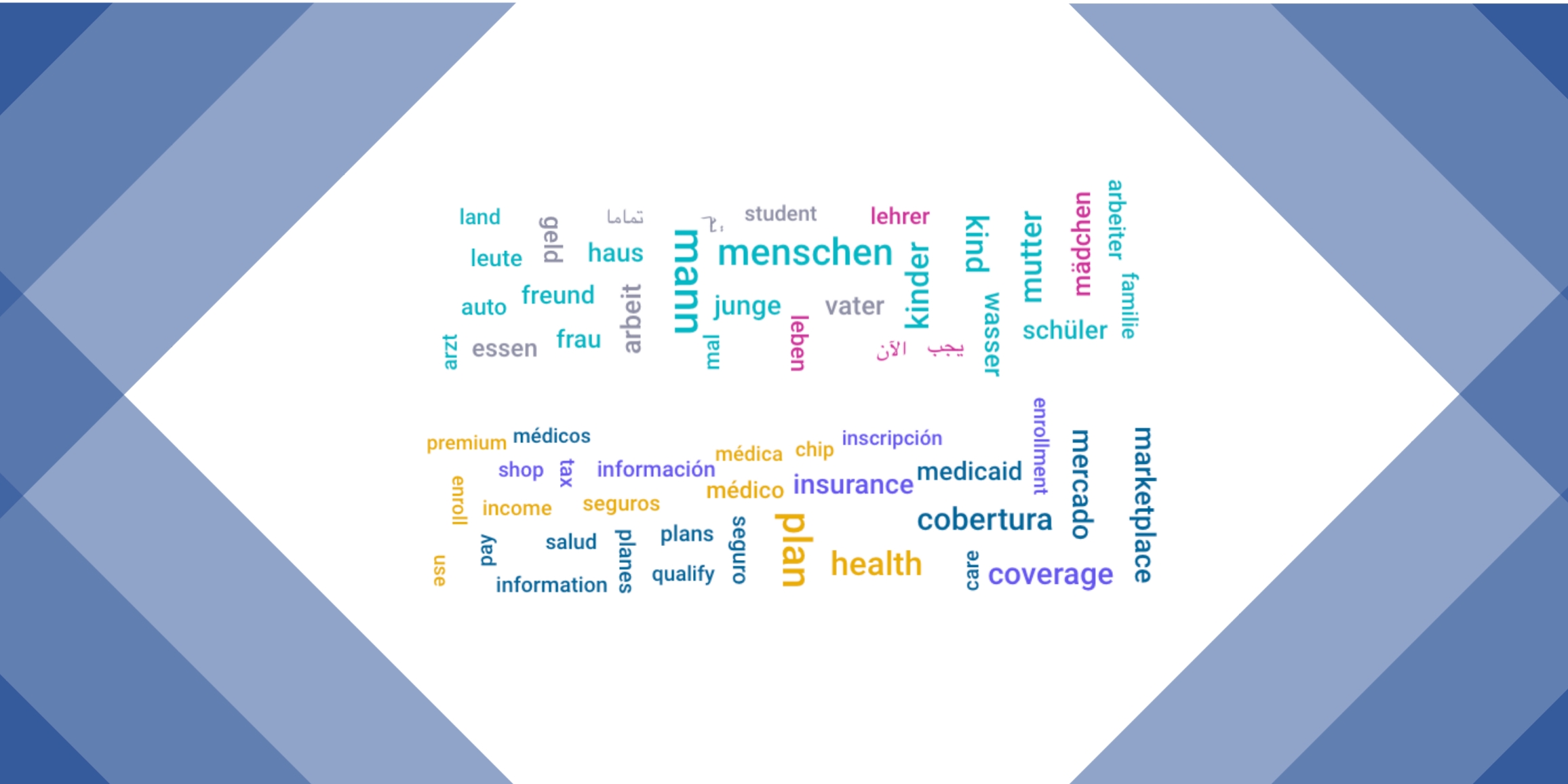
What can word clouds driven by NLP tell you about your training datasets? Here is how we create word clouds on TAUS Data Marketplace.
Author

NLP Research Analyst at TAUS with a background in linguistics and natural language processing. My mission is to follow the latest trends in NLP and use them to enrich the TAUS data toolkit.
Related Articles


11/03/2024
Purchase TAUS's exclusive data collection, featuring close to 7.4 billion words, covering 483 language pairs, now available at discounts exceeding 95% of the original value.

09/11/2023
Explore the crucial role of language data in training and fine-tuning LLMs and GenAI, ensuring high-quality, context-aware translations, fostering the symbiosis of human and machine in the localization sector.

19/12/2022
Domain adaptation approaches can be categorized into three categories according to the level of supervision used during the training process.