EPIC
Resources

People create vast amounts of data daily through many touchpoints in their usage of the IoT (Internet of Things) devices, often without even realizing it. Think of all the apps you use, messages you send, pictures you take and share. And these are just the byproducts of your leisure activities (that you might not necessarily want to use elsewhere). Now, try to imagine how much data you create as part of your work. If you are a translator or a language service provider, the amount of language data you generated over time while working on projects, building glossaries or translation memories, or even just translating your favorite song or paragraph from a book for fun, is immense. More importantly, even if some years have passed and those specific lines of text are no longer used for their original intended purpose, they still have value as training data for ML applications.
As data is being recognized more and more as an asset and a commodity, online marketplaces facilitating the exchange of this new type of goods are growing in number and popularity. One such marketplace is the recently launched TAUS Data Marketplace, a platform for language data monetization and acquisition. In this article, we look at the market for language data and how one can define the value of their dataset in order to set its price.
If we take the MarketsandMarkets’ prediction that the global Natural Language Processing (NLP) market will triple in size over the next few years, growing from $11.6B in 2020 to $35.1B in 2026, it is clear that there is a market for language data. The NLP models need great amounts of input in the form of text and speech to be trained. So what does that mean for producers of this kind of data?
It means that there is a great opportunity to re-use the language data you’ve accumulated over time as a new source of profit. Marketplaces are a great starting point for a number of reasons: anyone can list their data for sale for as long it fits the requirements and the sellers have a great level of control with minimum effort. Moreover, marketplaces do the heavy lifting in terms of marketing to prospective buyers, facilitating payments, and ensuring data security. They can also offer additional data enhancing services such as cleaning and anonymization like the TAUS Data Marketplace does, helping you get your data in the best possible shape.
The idea of additional income probably sounds great, but how much are we actually talking about? That brings us to one of the most commonly asked questions which is how to define the right price for a dataset. What is the monetary value of language data and which criteria play a role in determining the final price?
In the traditional language services setup, translation price is typically formed based on a number of factors:
Most of these don’t play a role when it comes to the price of translation as language data, simply because in the marketplace scenario, uploaded data is ready-made and once it is in the marketplace, it can be re-sold multiple times.
One of the good things about marketplaces is that thanks to the way they operate, they employ a self-regulating, dynamic pricing model based on demand and supply. The main factor in determining the price for a language dataset, therefore, is the availability of a specific language pair + industry domain + content type combination. So-called long-tail languages such as Xhosa or Kyrgyz can have a higher price per word compared to Swedish or Italian, regardless of the economic situation in their respective countries because they are considered rare and underrepresented. Even more so if the dataset in question covers in-demand domains like healthcare, multimedia, etc.
An example of supply-demand-driven comparative pricing is the Price Index that TAUS Data Marketplace uses. Established on the analysis of 35 billion words worth of language data in over 600 language pairs that were collected over 13 years, it currently covers more than 1,500 language pair + domain + content type combinations. The shown prices per word range between €0.0035/word for very abundant to €0.0065/word for very rare and are based on the overall availability for that specific combination in the marketplace. As new datasets get published to the marketplace, the price points are dynamically adjusted.
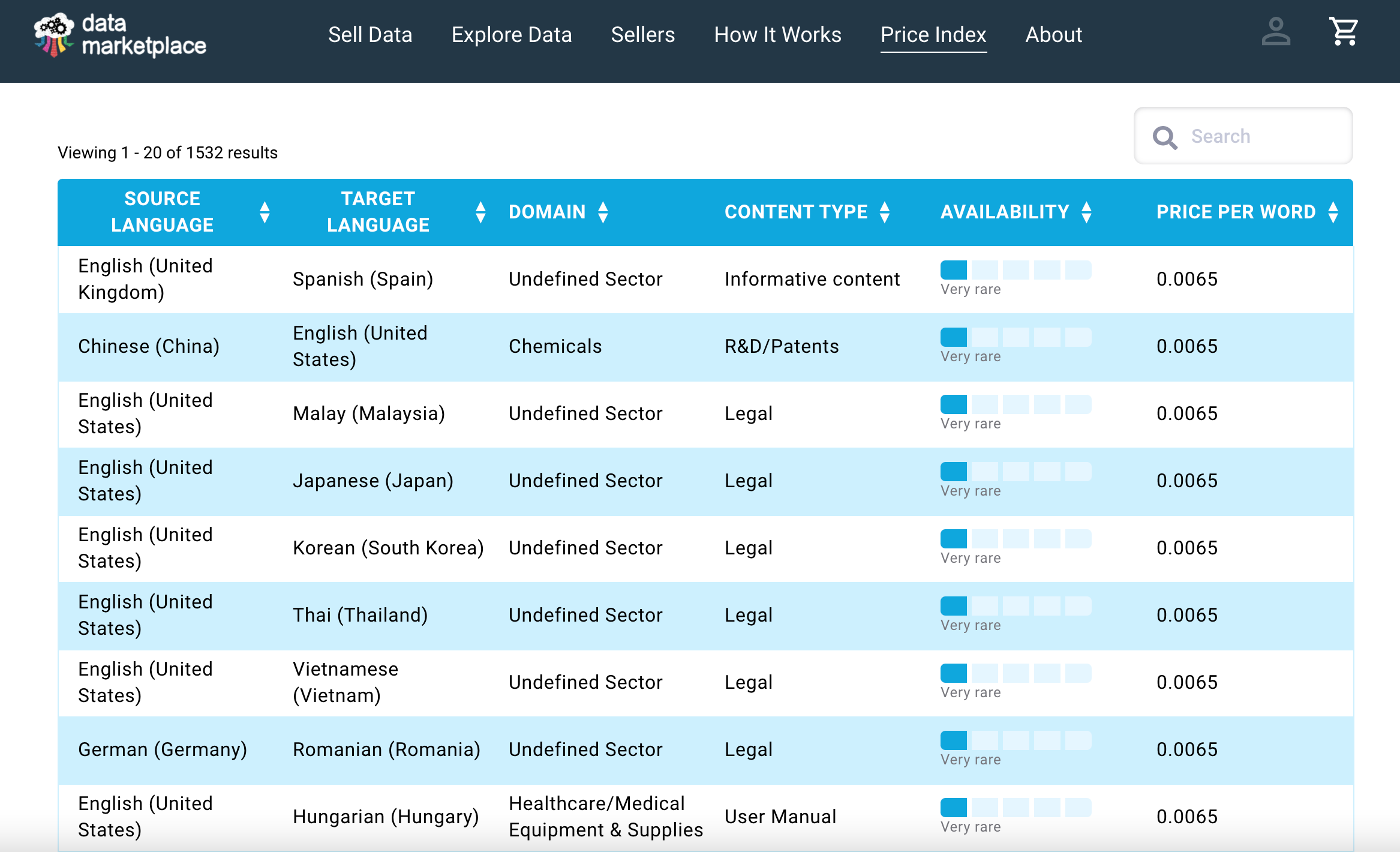
The Price Index functions as a suggestion and control mechanism to ensure a fair trading environment. However, it is up to the sellers to decide on the final price for each of their datasets. So, if you take the lowest price from the Price Index (€0.0035/word) and the highest price a data seller can set which is €0.15/word, it means that for a dataset of 10,000 words a seller can earn between €35 - €1,500. Not bad right, especially since this data would otherwise sit idle somewhere on your device or cloud. If you’d like to know more about the motivation to sell language data, check out the success stories from some of the existing data sellers.

Milica is a marketing professional with over 10 years in the field. As TAUS Head of Product Marketing she manages the positioning and commercialization of TAUS data services and products, as well as the development of taus.net. Before joining TAUS in 2017, she worked in various roles at Booking.com, including localization management, project management, and content marketing. Milica holds two MAs in Dutch Language and Literature, from the University of Belgrade and Leiden University. She is passionate about continuously inventing new ways to teach languages.