EPIC
Resources

Not so long ago, I was at the airport, listening to a voice announcing the gate change. I couldn’t help but notice that the sentences sounded somewhat unnatural as if parts of it were cut and pasted together. Shortly after, I had a chance to see backstage the technology used by a company providing natural voice announcements. I was surprised to learn that it consisted of cutting and pasting parts of pre-recorded sentences into new ones, with the guidance of native speakers. Not that I’m an expert in the field, but choosing for what seems a largely manual process appeared old-fashioned to me, in this age of data and technology.
You could say that the technology is not there yet, but it is. And I don’t mean only the Alexa’s, Cortana’s and Google assistants, but also the available open-source systems and algorithms, used both to empower research and support derivative work. In 2017, we wrote about this democratization of algorithms and concluded that machine translation is a simple sum of algorithms and data (see Nunc est Tempus). The algorithms and models are out there, up for grabs - statistical, hybrid, neural - the choice is yours. And what about the data? Google’s recent Massively Multilingual NMT research is proof of the leap forward that can be achieved when you have large volumes of language data. What still appears to be the main bottleneck is the lack of data in a particular target language or domain.
While generic engines perform well with a general-purpose text, a machine translating text in a particular linguistic domain will give the best results when trained with a customized data set, carefully selected to cover the vocabulary and semantic specificity of the content. A simple explanation is that the engine trained on data relevant to the domain will have a built-in bias towards that domain, and will deal better with issues like word sense disambiguation - determining which meaning of the word is the best fit in a certain context. Take for example the word virus and the different meaning that it has in software translations as opposed to the life sciences domain.
To address this lack of availability of domain-specific data and the growing number of engine customization use cases in the industry, we released the TAUS Matching Data clustered search technology earlier in 2019. It is a search technique that uses an example data set to search a data repository, calculate matching scores on segment-level and return high-fidelity matched data. That was also a perfect opportunity for us to test our own hypothesis - that the data today are just as relevant, if not more relevant than the algorithms.
For our experiment, we have chosen a well-known platform in the machine translation field - the WMT Workgroup, which posts a number of machine translation tasks every year. Each of the WMT tasks has a goal and a set of success metrics, inviting MT practitioners to perform experiments with their algorithms or data and to submit their results.
The shared task that was focused on domain adaptation and hence relevant to our hypothesis was the WMT16 IT translation task. The task provided both in-domain and out-of-domain training data, together with in-domain test data in seven languages for the IT domain.
The rules of the game are simple:
The in-domain training data provided in the WMT task (Batch1 and Batch2) consisted of 2,000 answers from cross-lingual hardware and software help-desk service. In order to test the performance of the in-domain IT corpus created with Matching Data technology, we used the WMT training data as the query corpus to select matching sentences from our vast language data pool (TAUS Data Cloud) and create our own IT training corpus for the selected six languages. That qualified our training as unconstrained.
This Matching Data was returned from the Data Cloud:
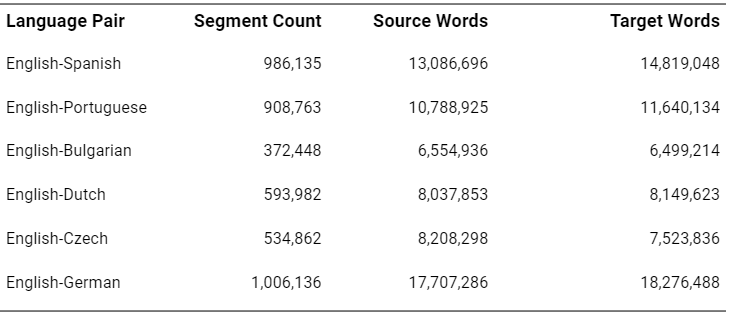
As for the system to train, we deliberately chose an open-source, vanilla Moses engine, and not a more advanced neural or hybrid system, so that the focus would be solely on the performance of the training data and not of the system itself.
After training the engine on the Matching Data IT corpus, we used the WMT test set (Batch 3) and reference translations to compare with our engine output and calculate a BLEU score.
Overall, the MT engines that were trained with the matching data corpora performed strongly across all language pairs. For three language pairs, they beat all the other systems submitted as part of the WMT 2016 IT task. For the other three languages, they were on par with the other submissions for the particular language pair.
What is more important with regards to our hypothesis, is that the matching data corpora outperformed all submissions where only WMT in-domain training corpora were used (constrained), regardless of the engine model (see the table below), proving that there is a guaranteed improvement coming solely from fine-tuning the data. What this also proves is the relevance of the data towards the set domain, even in a setup where a basic Moses machine translation system and a relatively small training set are used.
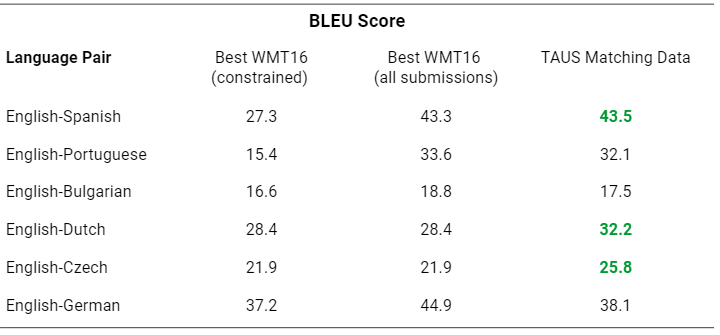
The scores and comparison are based on the system submissions available on http://matrix.statmt.org for the it-test2016 test set.
Adaptation of MT engines for domains is quite common these days. Most MT providers offer it as a service and so do the giants like Google (AutoML) and Microsoft (MS Business Translator). Whichever option you chose, you will first need to source the in-domain parallel training data. You can start by looking at the data that your organization collects, which is most likely not MT ready or search for a third-party provider that would be able to provide in-domain data, but that might still be too generic for your purpose.
Or, if you want to make sure to get training data that matches your specific needs, you can have TAUS perform data matching for you, based on your own query corpus - nothing can be more customized than that! Have a look at the corpora we already created in our MD Library, you might find a ready-made one that is just what you are looking for.

Milica is a marketing professional with over 10 years in the field. As TAUS Head of Product Marketing she manages the positioning and commercialization of TAUS data services and products, as well as the development of taus.net. Before joining TAUS in 2017, she worked in various roles at Booking.com, including localization management, project management, and content marketing. Milica holds two MAs in Dutch Language and Literature, from the University of Belgrade and Leiden University. She is passionate about continuously inventing new ways to teach languages.