EPIC
Resources

As data science methodologies increasingly become more technologically advanced, new tools are created within the realm of artificial intelligence (AI). One such emerging and increasingly commonplace tool is known as synthetic data. Synthetic data is artificial data created by a computer program, hence the name “synthetic”. Although synthetic data is not a novel concept, the technological resources and computing power we have today have made this type of data grow in popularity.
Synthetic data can be crucial to organizations where a specific kind of dataset is needed but its conditions cannot be met through naturally occurring or organic data. It is primarily used for training data generation, model training, testing purposes, and privacy concerns, given that it meets certain predefined conditions specific to its use case.
Given the large volume of data required to train machine learning models, oftentimes it can be difficult to acquire this data. Companies can have a tough time not only capturing data but also storing and handling it. Furthermore, labeling this data can also be a lengthy task often requiring dedicated resources. For these cases, producing synthetic data tailored to a specific use case can be a powerful alternative.
Synthetic data generation is a critical process that could potentially have a large impact on its application. Depending on the use-case, synthetic data should meet certain requirements when used in a production setting. Oftentimes, it is generated by a machine learning model, such as a deep learning model, for the sake of creating more training data. In most cases, statistical properties such as spread and distribution should be taken into consideration when attempting to mimic real-world data into synthetic data. Companies use a variety of techniques to generate synthetic data such as Monte Carlo simulation, deep learning models, decision trees, reverse-engineering techniques, and iterative proportional fitting.
For the case when real data does not exist, intuition on the underlying distribution of the dataset can greatly benefit during synthetic data generation. For example, if the distribution is known to follow either gaussian, poisson, exponential, or some other well-known statistical distribution, then random sampling from one of these distributions could produce synthetic data. Of course, the level of resemblance of the synthetic data to real data ultimately depends on the backhand knowledge of the data. However, when real data is available to mimic and the distribution parameters are known, Monte Carlo simulations can be applied.
Using deep learning to generate synthetic data is a good option when a very large set of data is needed and when the underlying distributions are not well-known. An example of a deep learning model that can be used to generate synthetic data is known as generative adversarial networks (GANs). GANs are a good option because they generate random variables from a given distribution. Using something called a generator, the model produces fake data from randomized inputs. This then gets fed into a discriminative network, which separates the fake data from the real data. Both the generator and discriminative networks train the model using forward and backward propagation to compare the synthetic dataset with the real one. The below diagram shows this system in action: 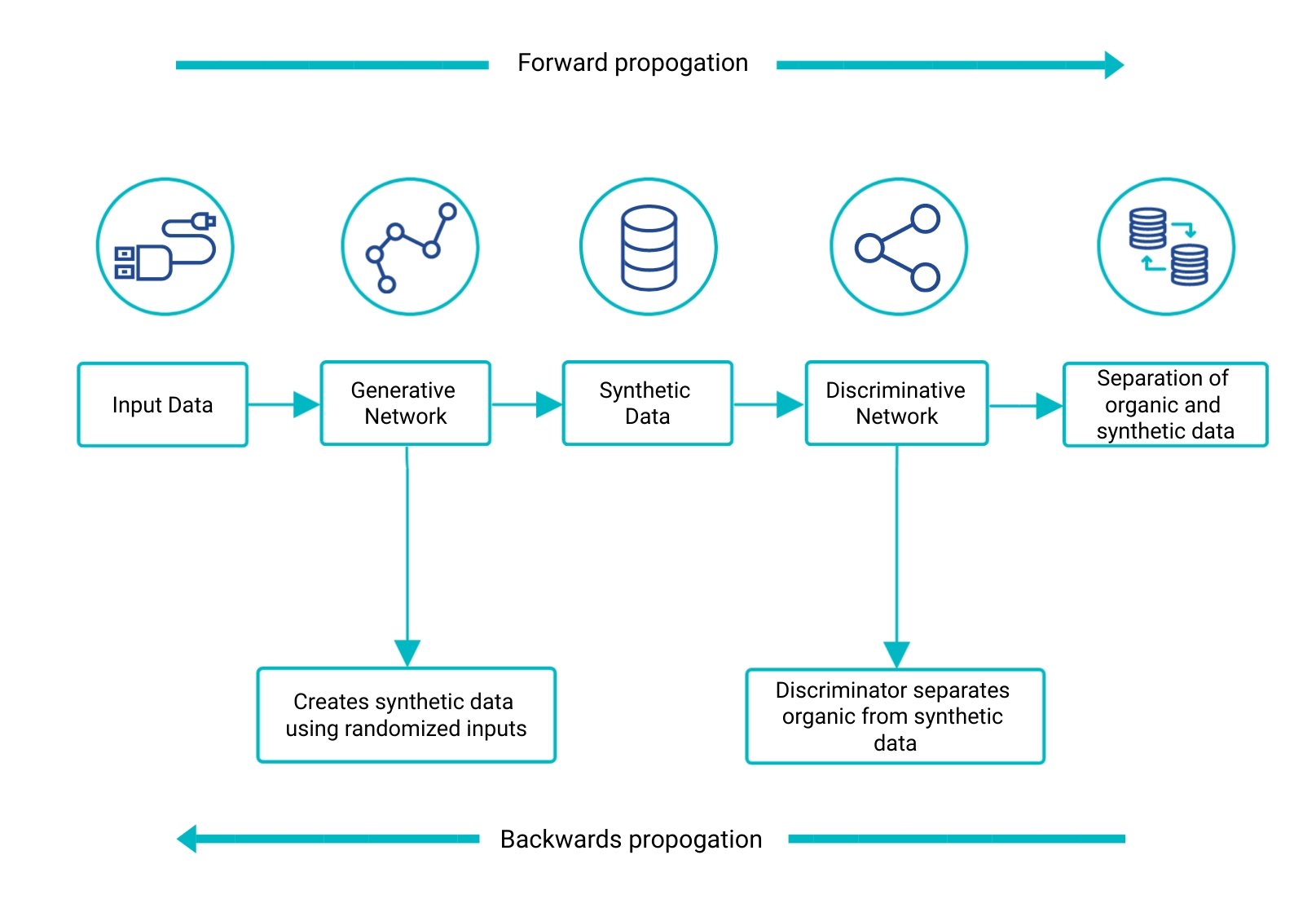
Organic vs Synthetic Data
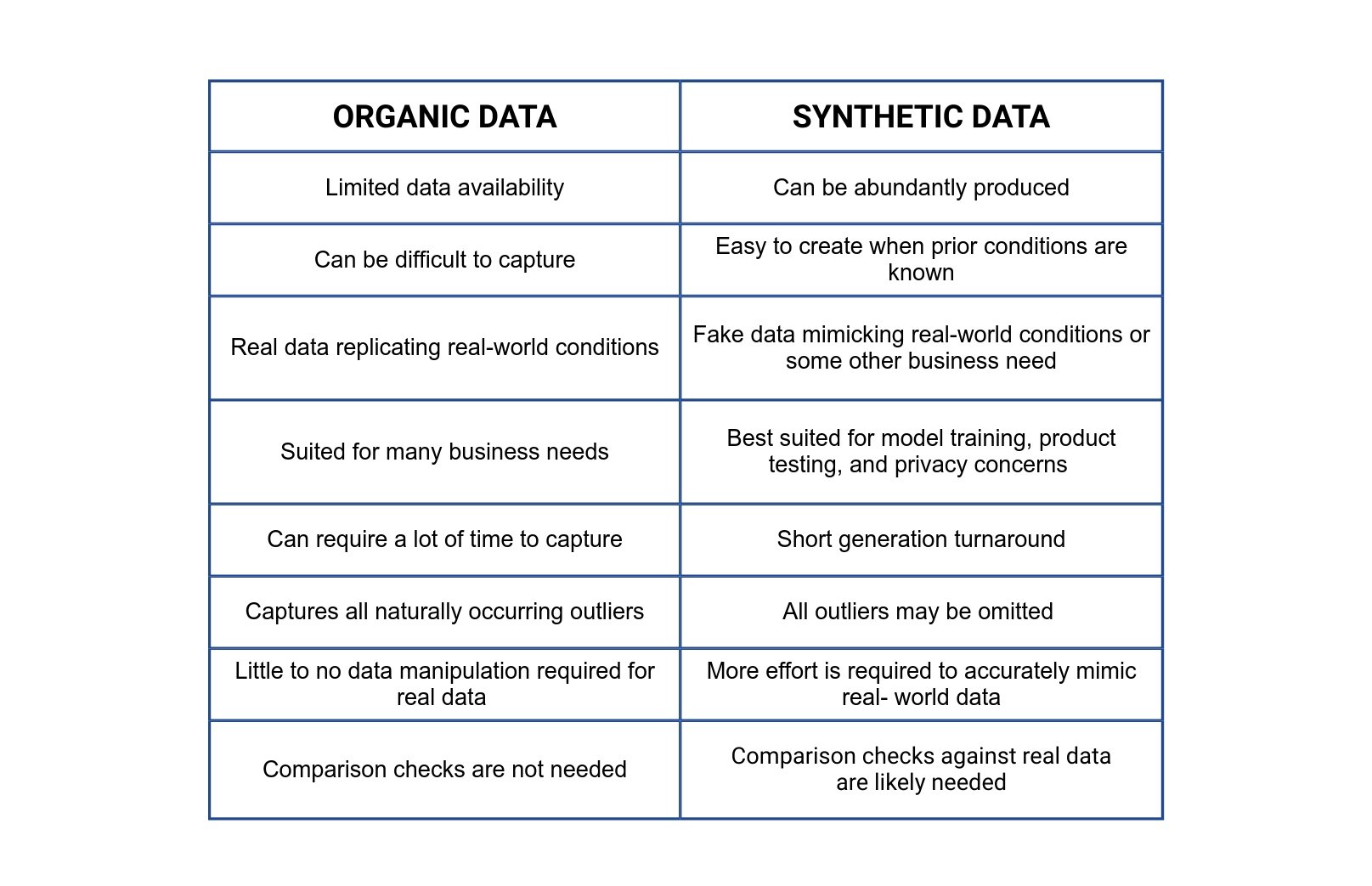
Organic data is the data that many of us are used to on a daily basis. As mentioned above, it is naturally occurring data that is produced by real-world phenomena. Organic data can be difficult to capture, especially in larger volumes. It can also require a lot of cleaning and tweaking to fit a given business need. Furthermore, sometimes a specific dataset may not be readily available or naturally occurring. To overcome these drawbacks, synthetic data can be used as an alternative. Both organic and synthetic data have their pros and cons, depending on the use case. The below table outlines some of the comparisons between both types of data:
Conclusion
Depending on the application, both synthetic data or organic data could deem useful. When organic data is not readily available or attainable for a specific application, synthetic data may be a viable option. Synthetic data can be generated through many different statistical or classical machine learning methodologies, such as a GAN, as seen above. An important factor to note during synthetic data generation is to follow the desired data’s distributions and statistical properties as closely as possible, including comparison checks. As the need for tailored training sets, product testing, and privacy concerns increase, synthetic data generation could be used to fit business needs.
.jpeg)
Husna is a data scientist and has studied Mathematical Sciences at University of California, Santa Barbara. She also holds her master’s degree in Engineering, Data Science from University of California Riverside. She has experience in machine learning, data analytics, statistics, and big data. She enjoys technical writing when she is not working and is currently responsible for the data science-related content at TAUS.