Resources
Training Data Sourcing Methods
04/10/2021
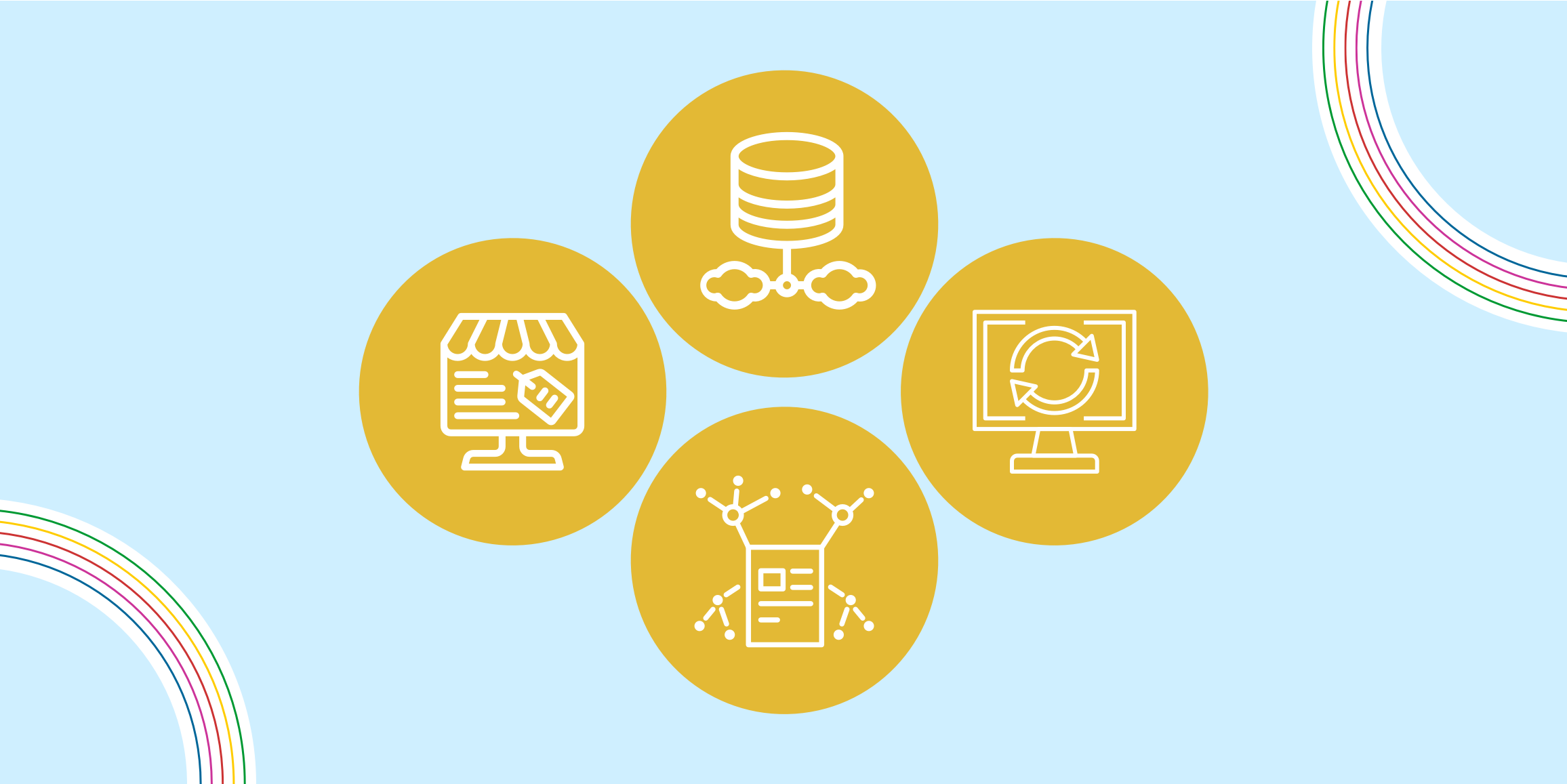
Training data can be sourced via synthetic data generation, public datasets, data marketplaces, and crowd-sourced platforms.
Author
.jpeg)
Husna is a data scientist and has studied Mathematical Sciences at University of California, Santa Barbara. She also holds her master’s degree in Engineering, Data Science from University of California Riverside. She has experience in machine learning, data analytics, statistics, and big data. She enjoys technical writing when she is not working and is currently responsible for the data science-related content at TAUS.
Related Articles


11/03/2024
Purchase TAUS's exclusive data collection, featuring close to 7.4 billion words, covering 483 language pairs, now available at discounts exceeding 95% of the original value.

09/11/2023
Explore the crucial role of language data in training and fine-tuning LLMs and GenAI, ensuring high-quality, context-aware translations, fostering the symbiosis of human and machine in the localization sector.

19/12/2022
Domain adaptation approaches can be categorized into three categories according to the level of supervision used during the training process.