EPIC
Resources

Machine learning (ML) is all around us. From your mail inbox spam detection, to text or document classification, to self-driving cars, to speech recognition, and more, machine learning algorithms are present in our everyday lives. A machine learning model is an algorithm that learns and predicts data automatically, without the need to be explicitly programmed. In this article, we will review the main factors to consider when selecting the right ML model, given your application and data.
Most machine learning algorithms typically fall into four categories of algorithms: supervised, unsupervised, semi-supervised, and reinforcement learning. The figure below shows the different machine learning algorithms that correspond to each machine learning scenario.
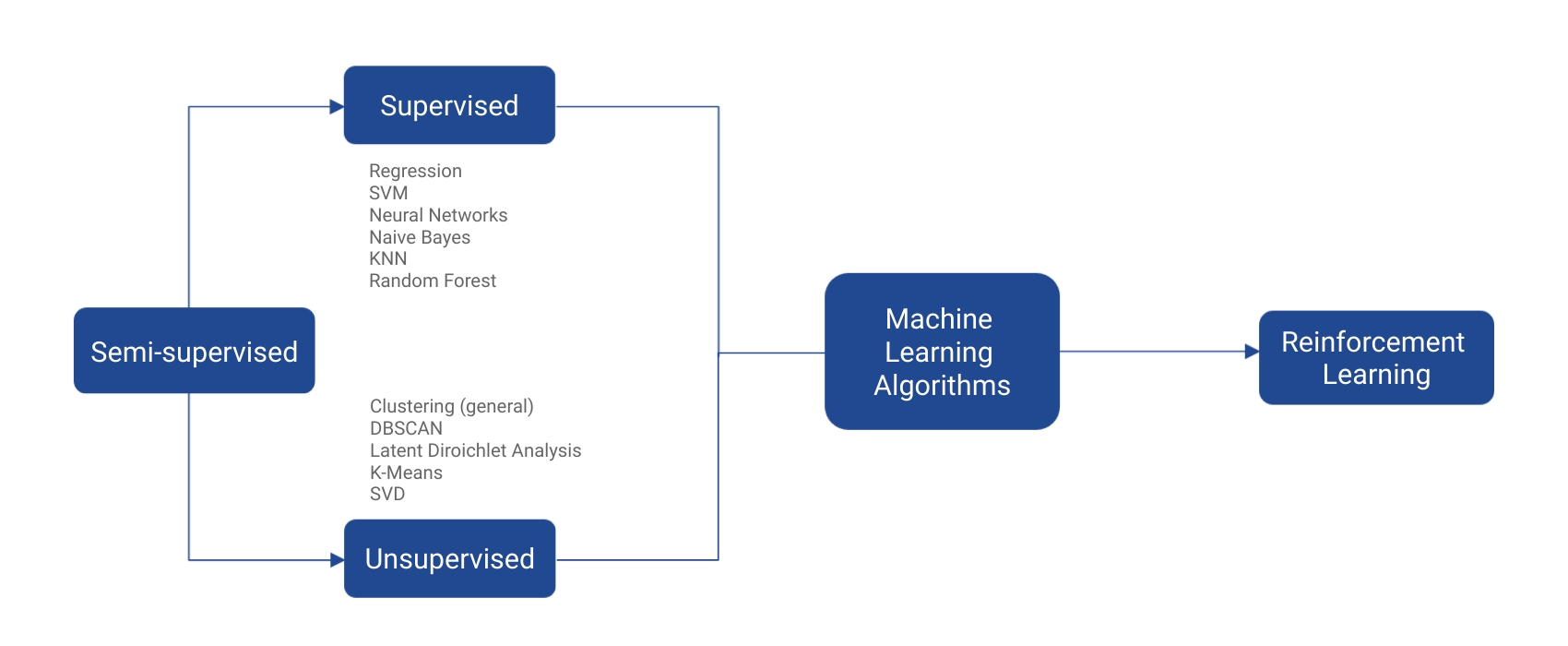
A supervised machine learning algorithm receives a set of labeled examples (also known as annotated data, which is data that has been tagged or classified) as training data and makes predictions for all unseen points. These algorithms attempt to model the relationship and dependencies between feature variables and their corresponding target variable. The outcome of a supervised model can either be categorical, binary, or continuous. A categorical variable consists of a distinguished number of classes, such as “German”, “Italian”, or “English.” Binary variables consist of a 0 or 1 outcome. Lastly, continuous variables are any real-valued output, such as a predicted temperature or cost of a house.
An unsupervised model receives unlabeled training data and makes predictions for all unseen points. Since no labeled example is available, it is difficult to quantitatively evaluate the performance of an unsupervised learner. These models are trained to identify the underlying patterns or structures of data. Common unsupervised techniques are dimensionality reduction, word and sentence embedding, and clustering models.
A semi-supervised model receives a mix of training samples, consisting of both labeled and unlabeled data and makes predictions for all the unseen points. Semi-supervised learning is common when unlabeled data is easily accessible but labels are expensive to obtain. Sometimes, both unsupervised or supervised algorithms can be used in this setting to assist the labeling process. An unsupervised model can be used to understand the underlying structure of the data and the supervised model can use those insights to make better predictions.
In reinforcement learning, the model performs a set of actions and decisions which is then used to learn and optimize decision-making. The model performs a sequence of decisions which is then met with either a reward or a penalty. Subsequently, these rewards or penalties are taken into consideration when making a decision. These models differ from supervised learning primarily in the aspect that they learn sequentially, i.e. the next output is dependent on the previous output. An example of a scenario that uses reinforcement learning is a chess game.

Given the task at hand, understanding what your predictor variable consists of is crucial in determining the correct model to select. Understanding if your outcome is categorical, continuous, binary, or unknown, can help you choose whether your model should be supervised or unsupervised. Furthermore, knowing whether you have labels or need labels to be created is important to help you narrow down between a supervised or a semi-supervised problem.
Identify the Characteristics of Your Data
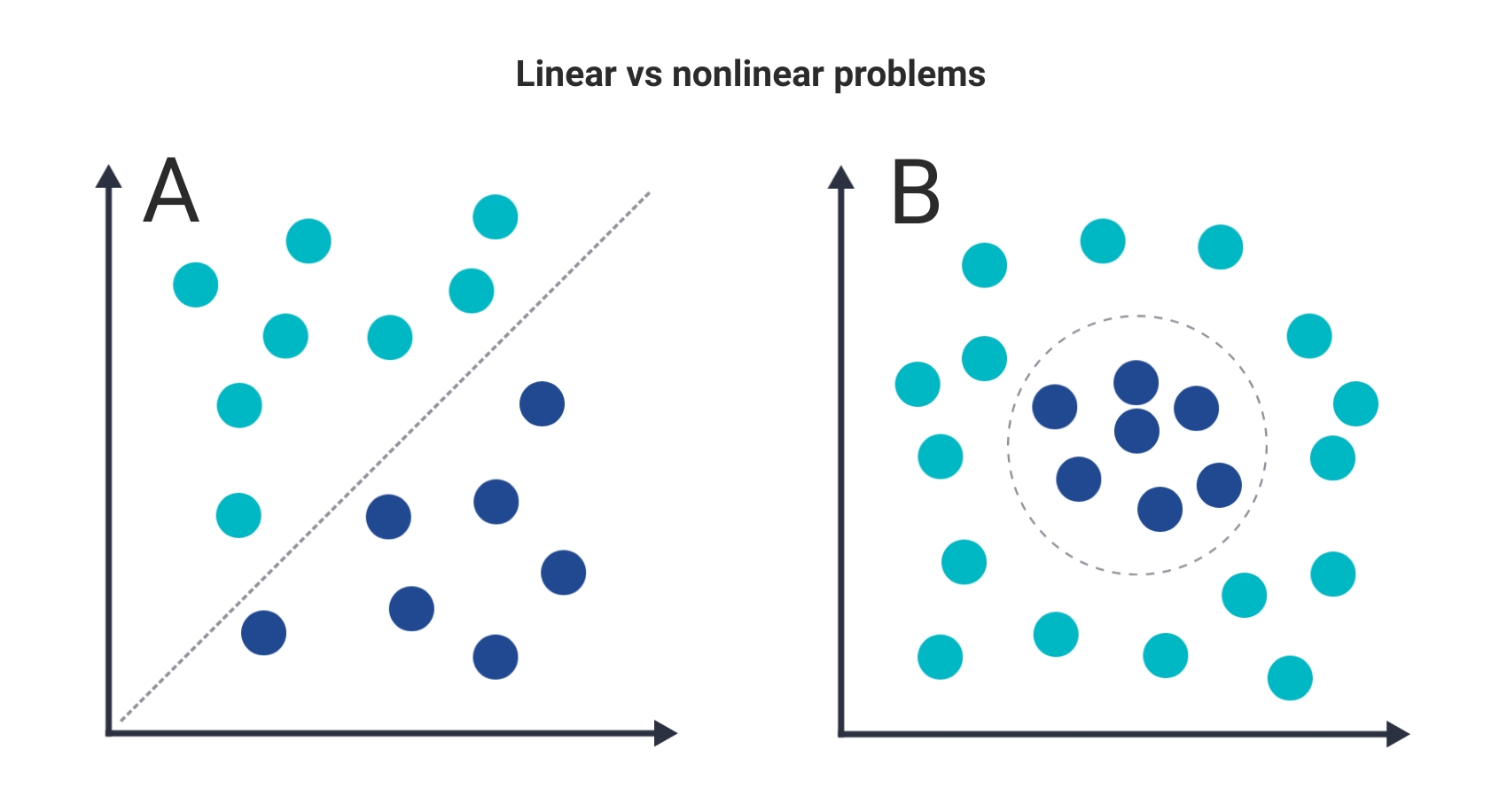
Understanding the underlying characteristics of your data can greatly help you choose an optimal model. Identifying if your data is either linear or nonlinear can help you understand your target function’s form. A linear equation has a polynomial degree of 1. Linear data is when the relationship between coefficients are linear and the features and predictor variables are constant. An example of linear data could be the relationship between height and weight. As a person’s high increases, generally, the weight increases, resulting in a linear relationship of data. Nonlinear data consists of data that is not linearly separable and the boundary is often a curve. Nonlinear functions are typically more versatile and powerful because they can represent a larger class of functions, however, they are more difficult to train.
If your features and your target variable have a linear relationship, choosing a linear model like regression, i.e. predicting a real-valued label, can be suitable. Furthermore, when a linear function can be reduced to two outcomes (0 or 1), logistic regression could be used. When your data is not linearly separable, algorithms like random forest or SVM can perform well. In addition, deep learning models are suitable for non-linear relationships which can use non-linear activation functions such as ReLU and sigmoid. An example of linearly separable and non-linearly separable data can be seen in the figure below, in regards to a SVM model.
Another characteristic of data to be aware of is the number of features, or the independent variables in the data that act as inputs for making predictions. For example, if we are trying to predict the test scores of students, the features may be the time it took to complete the test and how long each student studied. Oftentimes, many features can be redundant or unnecessary for your prediction problem. In these cases, it is best to remove them before training your model. If your data has a large number of features, the complexity increases so a more complex model will be suitable, such as deep learning or random forests. If your data has few features, a simpler model such as regression can be used.
A model with high bias will oversimplify the target function by simplifying assumptions. This often occurs when your data has too few features or consists of a small training set. As a result, this can yield a high error on both the training and testing sets. This is also called underfitting.
In contrast, a model with high variance will pay a lot of attention to training data and will not generalize well on unseen data. This can happen when there is a lot of noise in the training set and the model is capturing this noise as part of the target function estimate. The resultant takes away from the true signal of the data and leads to high variance. This is also referred to as overfitting. Bias-Variance tradeoff is the error that fluctuates depending on how high or low your model’s bias and variance are.
When you have a small training set, models with high bias and low variance will perform better than models with low bias and high variance. For this scenario, choosing a simple model is the way to go. For example, if you are training a classifier, logistic regression can be a good option. If your target variable is continuous, consider a linear regression model with simple weights and regularization. When training an ensemble classifier, limiting the maximum depth can help keep the model simple.
When your dataset is large, consider selecting more complex models such as KNN, SVM, or neural networks. Generally speaking, the more data you feed a model and the higher quality that data is, the better predictions the model makes. Hence, most machine learning models are suitable for a large training set. To reduce noise, consider feature or dimensionality reduction to reduce complexity. The early stopping technique during training can also help reduce variance in a large dataset. Lastly, implementing cross validation can help avoid the problem of overfitting.
Generally, the more your model trains the higher the accuracy will be. Hence, if you want a model with higher speed then the tradeoff is lower accuracy, and vice versa. Complex algorithms will require more training data and more training time, hence they will be slower to execute. If your problem needs to produce faster results, algorithms such as linear regression, logistic regression, and Naive Bayes are good models to choose from. If your problem deems accuracy more important, then algorithms such as deep learning models, SVM, and random forests are good options.
Given the size of your data and your preference for either speed or accuracy, either a simple or complex model will be useful. If your preference is speed, then a simple model will be more useful. On the other hand, if your preference is accuracy, then the tradeoff will be to use a more complex model to yield more accurate results, at the expense of time.
Depending on the desired outcome of your machine learning problem for a given application, either a supervised, unsupervised, semi-supervised, or reinforcement algorithm can be used. Understanding if your data is either linear or nonlinear can help you choose between models that take on linear or nonlinear forms. If you have a large dataset, a complex model will likely be needed and if your dataset is small, a simpler model can be used. Being aware of the impact of the bias versus variance tradeoff can help you to select an appropriate model to tune accordingly. Lastly, reflecting on the speed versus accuracy tradeoff can help you to choose an optimal model, depending on your preference of speed or accuracy.
.jpeg)
Husna is a data scientist and has studied Mathematical Sciences at University of California, Santa Barbara. She also holds her master’s degree in Engineering, Data Science from University of California Riverside. She has experience in machine learning, data analytics, statistics, and big data. She enjoys technical writing when she is not working and is currently responsible for the data science-related content at TAUS.