EPIC
Resources

Visual data plays an integral part in our society and technology today. A massive amount of images are processed daily, from using facial recognition to unlock your mobile phone to detecting lane departure while driving. Any technology processing image data is likely implementing image annotation. Image annotation is similar to data labeling but in the context of visual data such as video or images. Annotating images is the act of labeling objects within an image. This step is crucial for any machine learning supervised model training on image data for tasks such as image segmentation, image classification, and object detection. As the rate of visual data being processed continues to incline, annotating images according to its business application can deem to be a time-consuming and challenging task. Hence, it is worthwhile to carefully choose the best image annotation tools and techniques based on the task at hand.
Computer vision is an area in machine learning which focuses on making sense of images through identifying objects, similar to the way humans do. This approach attempts to mimic how the human visual system functions. Computer vision models perform pattern recognition during the training step where labels are learned and assigned. Deep learning has become the go-to algorithm for computer vision tasks due to its scalability and accuracy of results.
Image annotation plays a pivotal role in computer vision tasks. It tags features in images you want your model to recognize and use during training. That being said, there are a variety of techniques to utilize to improve a computer vision task. Outlined below are tips any data scientist working with visual data can apply to improve their image annotation task and model results.
Perhaps some of the most impactful errors occur in the beginning phase of building an image annotation-based model. Rushing through your model without fully understanding the underlying data can lead to erroneous annotations. To avoid this, it is best to scope out the noise and distribution of your dataset before feeding it into a model. It is also important to assess prematurely if the quality of your image data is good enough for your model to train on. Furthermore, understanding the ins and outs of your data will help you to identify the best annotation technique to use. These techniques are discussed below.
After familiarizing yourself with the nature of the data and the given task at hand, selecting the best annotation technique to fit your problem and dataset is a critical step.
The three most common image annotation types to train your computer vision model are image classification, object detection, and segmentation. Each of these image annotation types are described in more detail below.
Image classification is a type of image annotation where images are tagged or classified according to the presence of similar images in the same categories. In other words, given a set of images in a dataset that fall under a particular category, you classify the labels of unseen images and assess accuracy results. Because this task can be very challenging due to things like background clutter and image deformation, the data-driven approach involves exposing your model to many different images of each class to learn from.
The most popular algorithm for performing image classification is known as Convolutional Neural Networks (CNNs). CNNs are a type of deep learning neural network where images are fed in and a probability of an image belonging to a certain class is output. They work by identifying features in a set of images during the training phase of the network. One way we see image classification in the real world is in the healthcare industry. Image classification using deep learning is applied to CT or MRI images to classify organs or lesions. These images can deliver vital information to doctors, such as the shape and volume of organs. The figure below illustrates the structure of a CNN model and a demonstration of an example output.
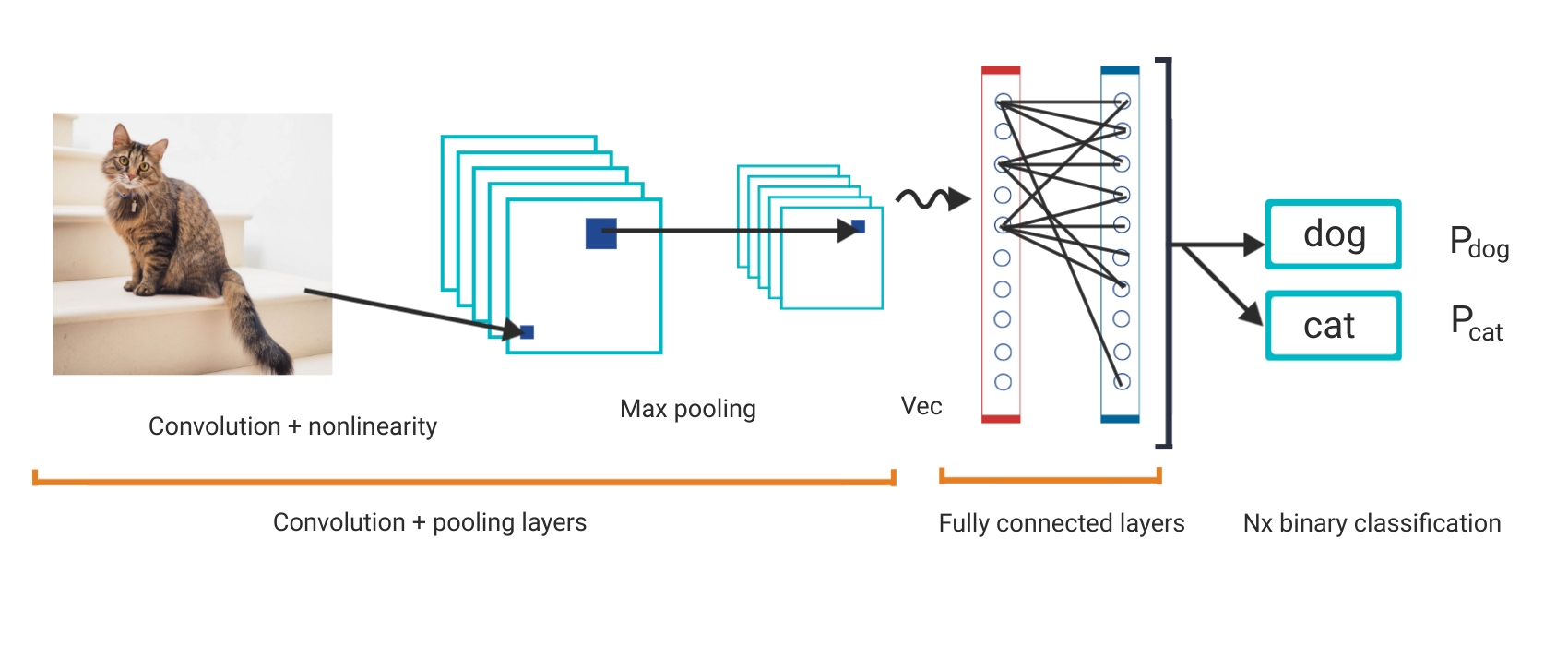 Object Detection
Object Detection
Object detection is the process of identifying variable objects within an image. Because of the increased complexity of having multiple objects within one image, this task is more challenging. Object detection differs from image classification primarily due to its capability of detecting multiple objects within a single image. Bounding boxes are used to pinpoint, or localize, objects within an image, defined by a point, height, and width. Once bounding boxes have been predicted, image classification can be applied to label the objects within the bounding boxes. An example of this can be seen in the image below, where there are four bounding boxes identifying different objects.
Two popular object detection algorithm families are R-CNN and YOLO. R-CNN stands for region CNN because of the model’s proposal of regions in an image where it believes relevant objects reside. YOLO, standing for You Only Look Once: Unified, Real-Time Object Detection, uses regression as a means to assign probabilities to identified objects. YOLO allows for real-time object detection due to its simple CNN approach of using a single network to define bounding boxes within an image.
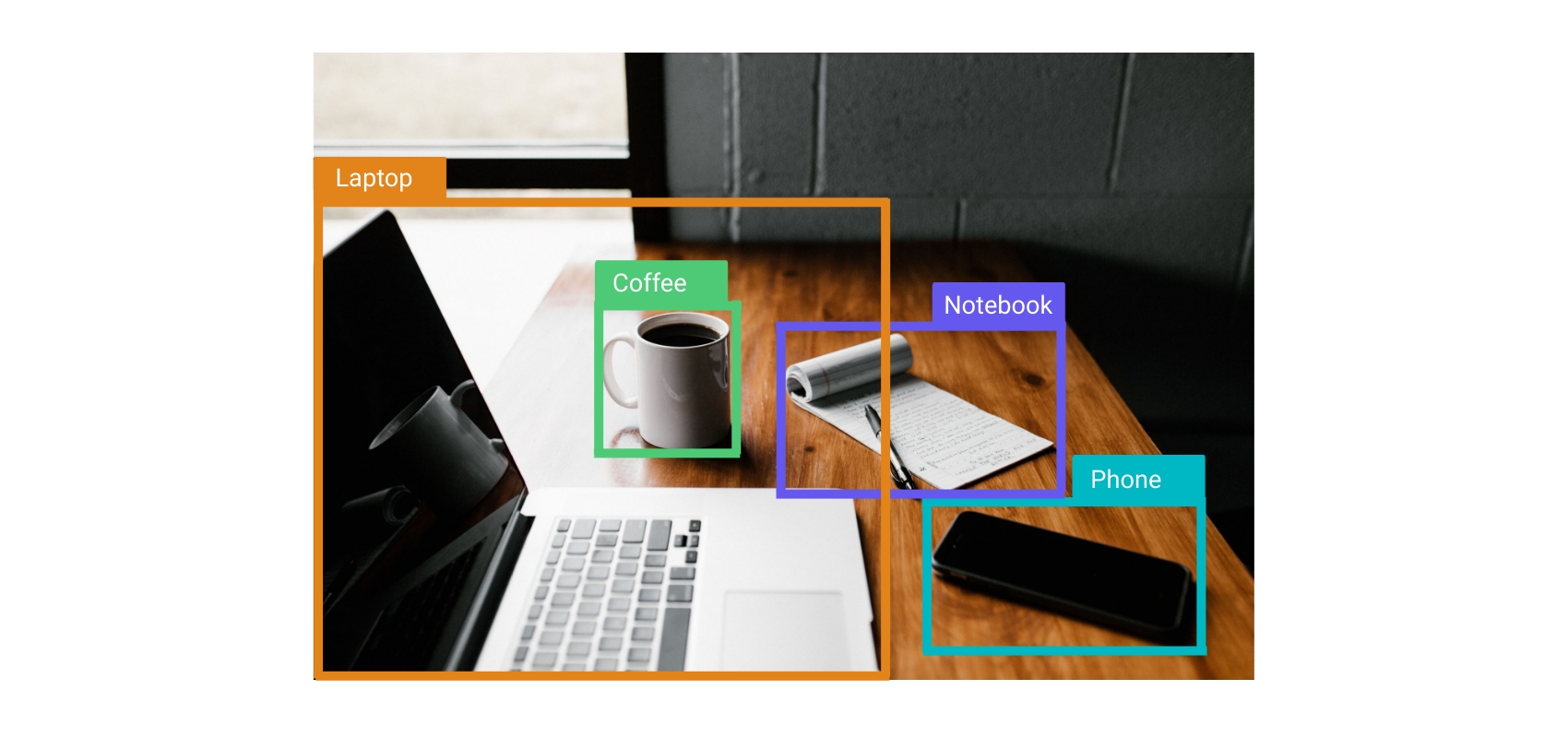
Image segmentation takes a new approach in comparison to object detection. Instead of drawing bounding boxes, image segmentation annotates each pixel within an image. Each pixel is assigned a boolean indicating whether that pixel is part of an object or not. The output of image segmentation will give you what is known as a mask image. This is simply a collection of pixels that are grouped together based on similar attributes.
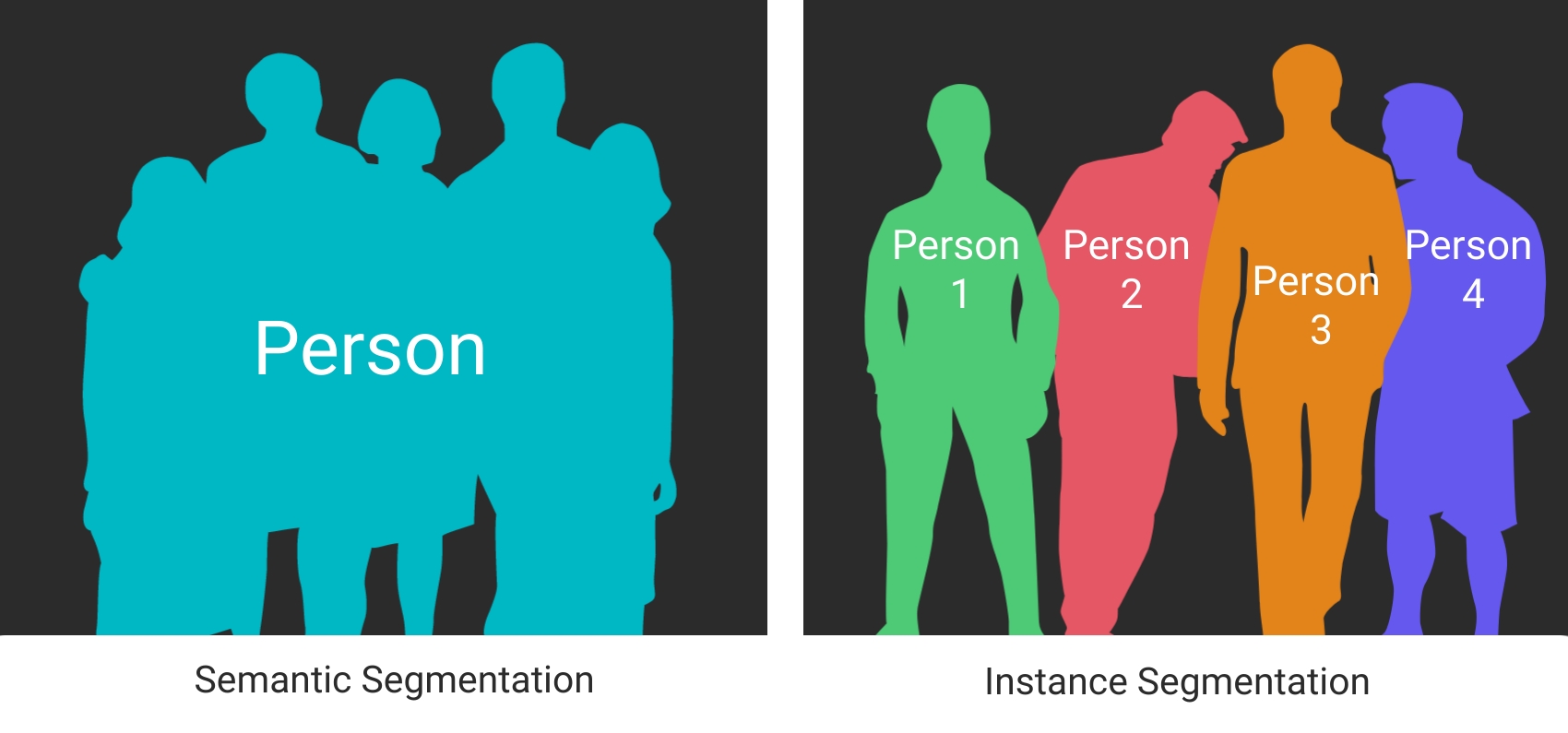
Within image segmentation, there are two overarching types of segmentation techniques. These are known as semantic segmentation and instance segmentation. Semantic segmentation will assign all pixels that are identified as part of an object in the same color, while pixels that are not classified as part of an object are a different color. In contrast, distinct objects in an image will have their respective pixels assigned to a single unique color, resulting in each object having a different color. The image below illustrates the difference in output between semantic and instance segmentation.
Apart from choosing the most relevant image annotation technique, evaluating your results can allow you to understand how accurate your predictions are. As image annotation tasks are related to classification, metrics like precision and recall are applicable. Precision, or the positive predictive value, is the ratio of the true positives to the total number of positive predictions. Recall, also called sensitivity or true positive rate, is the ratio of the number of true positives to the total number of relevant objects. These metrics are computed using the IoU (intersection over union) ratio, which is the ratio of the intersection between the predicted and ground truth bounding boxes. A preselected threshold can be set to determine whether your predicted bounding box is considered valid or not, yielding either a true positive, true negative, false positive, or a false negative outcome.
An image annotation task requires the use of computer vision techniques to identify images or objects within images. An alternative to using computer vision techniques is platforms where qualified annotators selected based on project specifications perform the tasks at hand. The TAUS HLP platform is one of the prime examples of such platforms. In the TAUS HLP Platform, humans perform a variety of annotation tasks which can increase accuracy as well as simplify the model evaluation process. In particular, community-sourced image annotation and collection services can be provided for projects of varying complexity and at scale with a special annotator community formed in line with given project guidelines.
In a regular project setup for the HLP Platform, the initial step is to identify and instruct annotators to perform the tasks. The community of annotators for each project is formed based on various criteria from product affinity to their native location depending on the project goal. They are then thoroughly trained on the specifications and guidelines of each annotation project.
Once the annotators are trained on how to annotate the data, they will begin annotating images on the platform. The HLP Platform, similarly to other data training and annotation platforms, is equipped with multiple tools which allow annotators to outline complex shapes for image annotation and can be further customized based on project requirements.
Depending on your image data and annotation goal, image classification, object detection, and image segmentation are powerful and common techniques to try. After building and training the appropriate model, using evaluation metrics like precision and recall will ensure the accuracy of your predictions.
.jpeg)
Husna is a data scientist and has studied Mathematical Sciences at University of California, Santa Barbara. She also holds her master’s degree in Engineering, Data Science from University of California Riverside. She has experience in machine learning, data analytics, statistics, and big data. She enjoys technical writing when she is not working and is currently responsible for the data science-related content at TAUS.