EPIC
Resources

Technologies such as Natural Language Processing (NLP), deep learning and computer vision have been thriving since data science has become well-established as a field of study and expertise. These developments have paved the way for the rise of machine learning (ML) to achieve the concept of artificial intelligence (AI). The transformative effects of these new technologies continue to be observed in our daily lives at a gradually increasing pace as we move into 2022.
The importance of data and how to work with data is becoming increasingly a common theme and making data science more accessible. Just a decade ago, data and AI were niche concepts that were only vaguely understood. Now we see that the methodologies of data and the science behind it are well-established and excellence in these areas is what most companies strive for. Despite the increasing understanding and popularity, research still shows that “everyone wants to do the model work, not the data work”. This allows for companies such as TAUS to emerge as pure data and data services companies to provide excellence in tailored data for AI solutions.
Traditionally each year we present an outlook into what language data for AI trends are likely to rise in the coming year. It’s time to look at what is in store for 2022 and list the trends to keep an eye on. The trends listed below are based on the Data Trends 2022 panel discussion at the TAUS Virtual Data Summit 2021, featuring Matthew Jackowski (Localization Director at eBay), Jonas Ryberg (Chief Globalization Officer at PacteraEDGE) and Watson Srivathsan (Product Manager at Amazon AI).
One of the main goals of machine translation researchers and developers has long been to create a single model that supports all languages, dialects, and modalities. These efforts have resulted in the emergence of multilingual models.
Multilingual models work based on the common approach that text phrases are embedded in the same vector space. In other words, any input language is transferred into a language-agnostic vector in a space, where all languages for the same or similar input would be mapped in the same area. Any input phrase with the same meaning would point to the same area in vector space.
Studies and research in this area have been ongoing for a while now. It’s expected that new and highly functional multilingual AI models will be trending in the near future. In pursuing this goal, multilingual training datasets play a crucial role and can, therefore, be listed as a trend by itself.
As it’s more common and easier to access bilingual or monolingual datasets, the generation of multilingual domain-specific datasets will be a trending topic of conversation, especially considering that most brands now strive to communicate with a much more global audience in an ever more local manner. Community-based platforms such as the TAUS HLP Platform where tailored datasets can be generated and annotated by a specially formed community of contributors can be used to get access to multilingual training datasets.
Language services providers (LSPs), individual translators, publishing companies and so many other players in similar sectors have now discovered that they hold the oil to make the machine learning engines run smoothly. The texts they have collected, generated, or processed over the years can now be used as training datasets, and this way turned into business assets. With the emergence of marketplaces for almost any type of data, from language data to geodata or marketing data, these new companies gain direct access to the market.
Along with this growing awareness, many success stories emerge. However, it’s good to note that having the data is only the initial step. Pre-processing the data in order to mold it into a usable format for AI training is the key element. Considering that most new companies do not really know how to handle or prepare data for AI training, marketplaces such as TAUS Data Marketplace offer cleaning and anonymization services for every uploaded dataset.
Artificial intelligence needs data diversity. This topic can be addressed in two folds: diversity in types of data and diversity to eliminate bias in data.
Training datasets can come in many forms, from text to speech, image, multimedia, and so forth. Text data is more common than all the other forms of available datasets on the market. However, with the changing user habits due to highly digitalized daily environments (and with that decreasing attention spans), voice messages, commands or images and memes are becoming the preferred method of communication both online and offline. To cater to these needs, services supported by AI are required. Some good examples can be the voice assistants and voice-to-text features in mobile phones. To improve these systems, more and more speech data is needed and, as these services are brought to a more global market, more diversity in the languages for voice data is needed.
In order to provide these services for everyone, regardless of gender, origin, age, race, and physical restrictions such as speech impediments, diverse voice datasets should be fed into the AI systems. This is key in providing a bias-free experience for all users.
However, finding voice data is harder than text data. Even if it can be found, finding it with the level of diversity needed in terms of languages, dialects, personas and conversation types and domains remains to be highly challenging. It can be overcome with custom datasets created by a specially formed group of people and taking all the points mentioned above into account. Such services are offered through platforms like the TAUS HLP Platform.
A new branch of AI approaches, called lifelong learning machines, is being designed to pull and feed data continually and indefinitely into AI systems. A lifelong learning system can be defined as a model that can efficiently and effectively retain knowledge it has learned from other tasks and selectively transfer it to be used in the learning of new tasks. In basic terms, lifelong learning machines defy forgetting in classification tasks.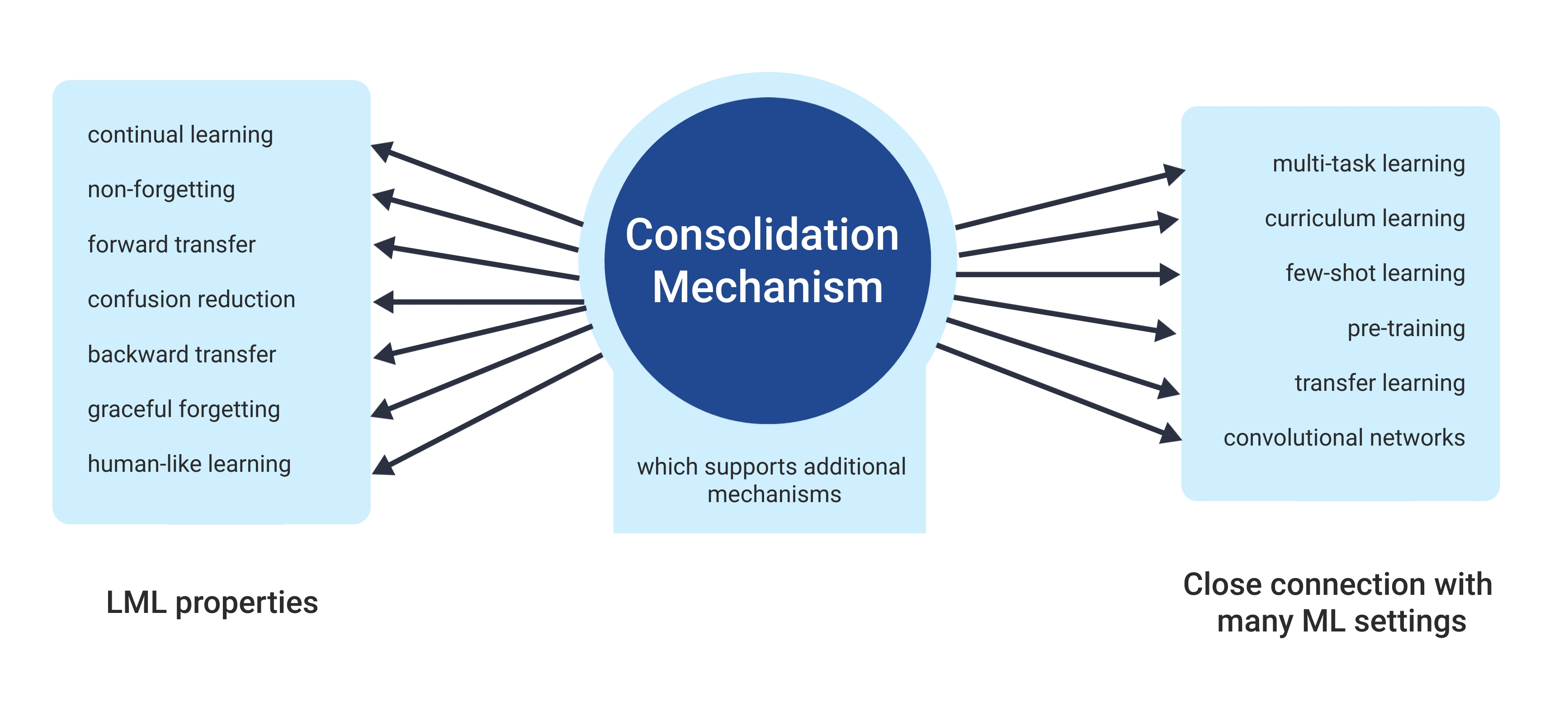
Researchers at Western University, Canada present this mechanism with the above diagram in their paper called A Deep Learning Framework for Lifelong Machine Learning.
Generally, the concept of lifelong learning is concerned with developing techniques and architectures enabling the machine learning models to learn sequentially without the need to re-train from scratch. Practical examples such as chatbots and production lines can be given to present the scope of solutions that can be created using lifelong learning methods.
Lifelong learning is still a fairly new topic and more research and development is likely to happen in 2022 and beyond.
The future is definitely data-centric, more so than ever. But data on its own cannot do the magic. It seems like we will be seeing more data enhanced with professional pre-processing; data that is multilingual; data that is diverse in representation and format; and systems that learn on their own. In addition, more providers of all of these types of data will pop up.
It’s a given that in 2022, an increasing amount of exciting data science applications and research will take place with the convergence of these transformative technologies and concepts that augment and complement each other.

Şölen is the Head of Digital Marketing at TAUS where she leads digital growth strategies with a focus on generating compelling results via search engine optimization, effective inbound content and social media with over seven years of experience in related fields. She holds BAs in Translation Studies and Brand Communication from Istanbul University in addition to an MA in European Studies: Identity and Integration from the University of Amsterdam. After gaining experience as a transcreator for marketing content, she worked in business development for a mobile app and content marketing before joining TAUS in 2017. She believes in keeping up with modern digital trends and the power of engaging content. She also writes regularly for the TAUS Blog/Reports and manages several social media accounts she created on topics of personal interest with over 100K followers.