EPIC
Resources

The discipline concerned with extracting information from text data is known as natural language processing, or NLP for short. NLP has many different use cases in artificial intelligence (AI) and machine learning (ML) tasks. It can be defined as the process of analyzing text data. Text processing is a pre-processing step during training data preparation for any text-based machine learning model, such as a natural language processing (NLP) model. Some common use-cases of NLP include spam filtering, sentiment analysis, topic analysis, information retrieval, data mining, and language translation.
Why is NLP Important?
Much of the technology consumers use on a day-to-day basis contains some sort of NLP-based model behind the scenes. In fact, text data has become very useful for companies to understand how consumers interact with their product or business through deriving text-driven insights. This is because users interact with the technology by inputting text data, such as writing emails, sending text messages, posting on social media, etc. An example of this is predictive typing suggestions one can see on an iPhone or in a Gmail account. To suggest a response or the next word in a sentence, the technology behind the application uses a model that looks at large-scale text training data.
Hence, text data can be considered as an important factor for human communication today. From emails to text messages to annotated videos, text data is everywhere. Furthermore, NLP has allowed for the creation of language models. Language or translation models power NLP-based applications which can perform a variety of tasks, such as language translation, speech recognition, audio to text conversion, and so on. Nowadays, there exist platforms for enriching language data and making it AI-ready through techniques such as annotation, labeling, etc. TAUS HLP is one such platform where a global community of data contributors and annotators can perform a variety of language-related tasks.
NLP Tips
After understanding what NLP is and why it matters, we now look to understand some methods and tips during model pre-processing and building. These methods could improve an ML-based language model to ultimately extract better text-based insights. Three important tips to consider when building any NLP model include proper text data pre-processing, feature extraction, and model selection.

1. Pre-processing
Before we feed any text-based machine learning model with data, we need to pre-process this data. This means we clean our data to remove words with little meaning to be able to capture meaning more appropriately. This step includes the removal of stop words, capitalization normalization, punctuation, tags, etc. The techniques outlined below are commonly used text data preprocessing methods:
2. Feature Extraction
Once our data has been cleaned after pre-processing, we now look to feature extraction. Feature extraction prepares the data for model use through categorization and/or organization. Some common ways to perform text feature extraction are count-based vectorization and word embeddings.
Vectorization is the process of mapping text data into a numerical structure. This can ultimately optimize a model by speeding up compute time and outputting more accurate results. One of the most common vectorization techniques is bag of words (BOW). BOW focuses on the number of occurrences per word in a document. This method encodes a unique word from a corpus of vocabulary to a unique number and maps its value to the count of its frequency.
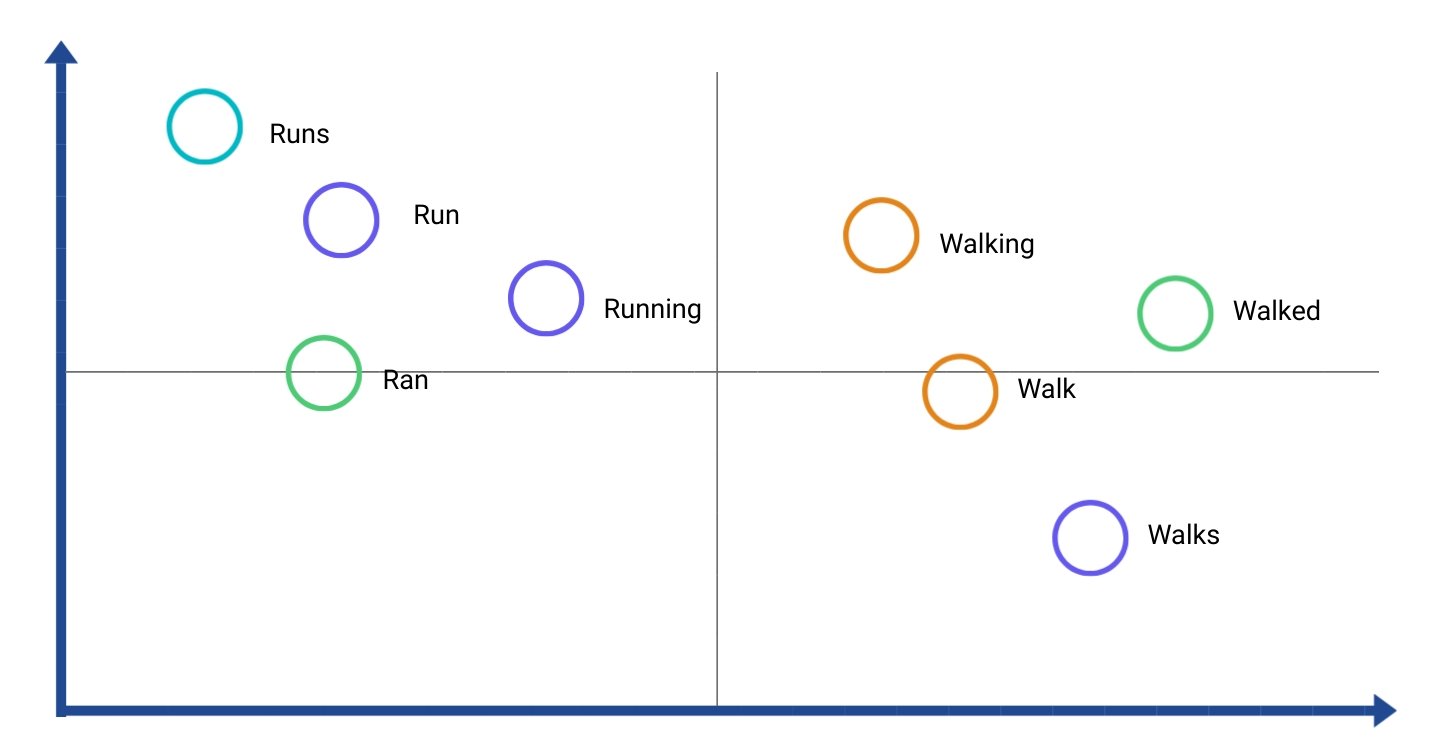
TF-IDF vectorization is another text feature extraction method where the relative frequency of a word is computed. In other words, the frequency of a given word appearing in a given document is compared across all documents in the corpus. This particular technique is common in applications such as information retrieval, search engine scoring, and document clustering. The biggest drawback, however, of both BOW and TF-IDF is that both leave out the contextual meaning of words.  One approach to make up for this problem is word embedding. Word embedding captures the relationships between words, thereby storing contextual meaning. Using a vector space structure, words that are related to each other are paired closer together. One way to implement this is by using Word2Vec, a popular technique that learns word embeddings in a corpus. Examples of corpora containing language data can be seen in the TAUS Data Marketplace, where sentence embeddings are used for data cleaning purposes. The example diagram below illustrates word embeddings in a vector space, where similar words are in close proximity with one another.
One approach to make up for this problem is word embedding. Word embedding captures the relationships between words, thereby storing contextual meaning. Using a vector space structure, words that are related to each other are paired closer together. One way to implement this is by using Word2Vec, a popular technique that learns word embeddings in a corpus. Examples of corpora containing language data can be seen in the TAUS Data Marketplace, where sentence embeddings are used for data cleaning purposes. The example diagram below illustrates word embeddings in a vector space, where similar words are in close proximity with one another.
3. Model Selection
The third and final tip of NLP is choosing the appropriate model for your text-based model. The first thing to do is to assess your output or target of your model. In a text-based setting, a supervised learning approach using a classification model is common. Next, determine the volume of your data. Deep learning approaches are often better suited for large volumes of data, whereas classical supervised machine learning works better with a smaller volume of text data. Lastly, consider multiple models and assess the best outcome. Ensemble methods in machine learning consist of using a combination of models rather than relying on a single algorithm. For example, the random forest algorithm uses multiple decision trees to output a single aggregated output prediction.
After choosing and testing different approaches, model evaluation is an important last step to assess how well your model performed. Techniques like cross-validation (training on multiple subsets of the training data in multiple iterations) and grid-search (finds the best set of parameters across all combinations in a grid) can help to assess and fine-tune the results of your model. Furthermore, if optimal results are not achieved, reassessing your data pre-processing during the initial step is a good place to evaluate. Perhaps further text processing optimization is required for the model to better understand the text data and perform more accurate predictions.
Summary
In conclusion, the three NLP tips outlined above can have a great effect on your text-based model and output. Pre-processing text data helps to extract, clean, and give structure to a body of text. Feature extraction assigns meaning to words through vectorization and word embedding methods. Model selection uses the results of the first two steps to learn and produce predictions on unseen text data.
TAUS can help you through all of these text data processes. Contact our team of experts for a custom solution for your specific needs.
.jpeg)
Husna is a data scientist and has studied Mathematical Sciences at University of California, Santa Barbara. She also holds her master’s degree in Engineering, Data Science from University of California Riverside. She has experience in machine learning, data analytics, statistics, and big data. She enjoys technical writing when she is not working and is currently responsible for the data science-related content at TAUS.