Resources
NLP-driven Word Clouds in Data Marketplace
What can word clouds driven by NLP tell you about your training datasets? Here is how we create word clouds on TAUS Data Marketplace.
Bilingual, NLP-driven word clouds are now available in TAUS Data Marketplace. In this article, we discuss what word clouds are and what they can tell us about the contents of a document containing bilingual text data.
When it comes to understanding the contents of large collections of data, visualization is one of the key techniques that many organizations and individuals rely on. Choosing the right visualization method is crucial when attempting to convey certain kinds of information about a dataset that either its creators or users find important or interesting. For example, using different shades of a color on a map of the world is a great way to illustrate global population density, while a population pyramid can tell us a lot about the demographics of a certain region with regards to age and sex. Datasets composed of text, however, contain a very different kind of data - they are made up of words and sentences rather than numerical variables.
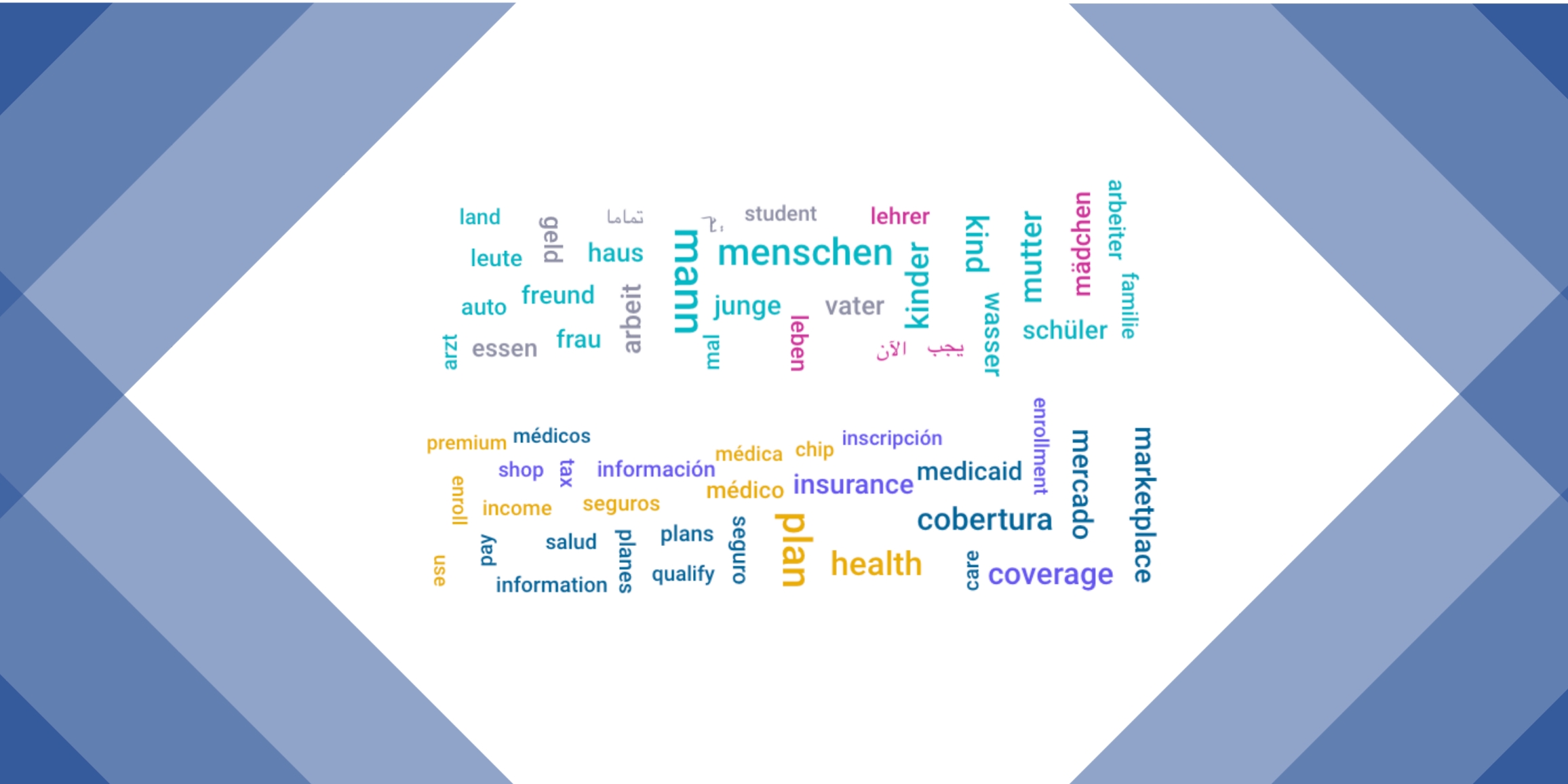
One way to visualize such data is to use word clouds. A word cloud is a simple, weighted visual representation of the vocabulary contained in a textual dataset that allows us to estimate the contents of the data at a glance. It contains the most frequently occurring words in the data, with more frequent words appearing larger in size than less frequent ones. Additionally, word clouds can contain frequency counts for each word as well - on document sample pages, for example, you can see the number of times a certain word occurs in the document by hovering over it with the mouse pointer. You can try this yourself by browsing the documents on the Marketplace sellers page.
Additionally, word clouds provide excellent insight into the domain of a text document. By inspecting a document’s word cloud, you can immediately see whether the vocabulary matches with what you would expect to find based on the dataset’s domain labels. For instance, if a document comes from the Healthcare / Medical Equipment & Supplies domain and the word cloud contains words like “treatment”, “clinical”, and “patients”, then you can be sure the document in question contains high-quality, domain-specific data.

A word cloud based on this article and its Hungarian translation (machine- generated)
How it works
Generating word clouds for bilingual documents might sound like a relatively simple task, but in reality, there is a lot going on under the hood. TAUS applies natural language processing techniques to produce high-quality word clouds that represent the contents of each document in the best possible way.
All of the data in the TAUS Data Marketplace comes in the form of sentences, so the first step in the generation of our “NLP-driven” word clouds is to split these into word-level units, also known as tokens. This process, called tokenization, requires specific solutions for almost every language and can get quite tricky when dealing with languages with logographic writing systems such as Chinese. This is why we rely on the spaCy NLP library, which allows us to tokenize data in dozens of different languages quickly and efficiently.
Having obtained a list of all tokens in a document, some additional filtering must be applied so that only the most important content words are retained. Therefore, the next step is to remove stop words, which include short function words such as articles (“the”, “a”, “an”), prepositions (“to”, “from”, “in”, “on”, etc.), and words that are common in all kinds of texts, such as “was”, “were”, and “can”. For this, we use a combination of lists of stop words provided by spaCy and a collection of such words that we maintain ourselves. Naturally, this must be done separately for every single language in our database. In addition, tokens that convey little or no information, such as digits and single-character tokens, are also removed.
Following stop words removal, the number of times each content word occurs in a given document is counted and saved in a frequency table. To obtain the final counts for a bilingual document, we merge the frequency data from both the source and the target language and retain only the most frequent entries. These counts indicate how many times each token occurs in the document and are used for the generation of word clouds on the Data Marketplace website.
Conclusion
Word clouds are a simple, yet effective way to visualize textual data in a clear and easily digestible manner. By adding them to TAUS Data Marketplace, we hope to improve the user experience so that both data sellers and buyers can gain a better understanding of the contents of their documents. Take a look at the word cloud on one of our document sample pages to explore the data yourself.
Author

NLP Research Analyst at TAUS with a background in linguistics and natural language processing. My mission is to follow the latest trends in NLP and use them to enrich the TAUS data toolkit.
Related Articles


11/03/2024
Purchase TAUS's exclusive data collection, featuring close to 7.4 billion words, covering 483 language pairs, now available at discounts exceeding 95% of the original value.

09/11/2023
Explore the crucial role of language data in training and fine-tuning LLMs and GenAI, ensuring high-quality, context-aware translations, fostering the symbiosis of human and machine in the localization sector.

19/12/2022
Domain adaptation approaches can be categorized into three categories according to the level of supervision used during the training process.