Resources
Using TAUS QE - Off The Shelf
These days Quality Estimation (QE) is a central part of the Machine Translation industry. Whether you use it to reduce costs on human reviewers, compare the performance of machine translation engines, or speed up your post-editing pipeline, you can’t deny its vital place in any translation business.


Learn how TAUS uses LLM-powered Automatic Post-Editing and Quality Estimation to automate MT review, cut costs, and boost translation quality.
May 15, 2025

Discover EPIC by TAUS: an AI-driven tool combining Quality Estimation and Automatic Post-Editing for optimized, cost-effective, and high-quality translation workflows. Try it out today.
Mar 26, 2025

Is Quality Estimation the next big thing in translation? Learn how QE improves MT accuracy, streamlines workflows and saves costs for LSPs and enterprises.
Feb 13, 2025
MORE BLOGS
All
DATA FOR AI
EVENTS
FOOD FOR THOUGHT
MACHINE TRANSLATION
PRESS RELEASES
PRODUCT UPDATES
QE & APE
These days Quality Estimation (QE) is a central part of the Machine Translation industry. Whether you use it to reduce costs on human reviewers, compare the performance of machine translation engines, or speed up your post-editing pipeline, you can’t deny its vital place in any translation business.
Jul 04, 2025

Discover how AI and innovation are transforming the localization industry and challenging traditional methods.
Jun 03, 2025
Learn how TAUS uses LLM-powered Automatic Post-Editing and Quality Estimation to automate MT review, cut costs, and boost translation quality.
May 15, 2025
Discover EPIC by TAUS: an AI-driven tool combining Quality Estimation and Automatic Post-Editing for optimized, cost-effective, and high-quality translation workflows. Try it out today.
Mar 26, 2025
Is Quality Estimation the next big thing in translation? Learn how QE improves MT accuracy, streamlines workflows and saves costs for LSPs and enterprises.
Feb 13, 2025

Celebrating the 20th anniversary of TAUS this month caused the team to look back at the predictions and outcomes so far. What have we achieved? What went wrong?
Nov 21, 2024

Unlock cost-effective translation workflows using Quality Estimation and Large Language Models for faster, high-quality results and discover how to optimize your translation process.
Sep 17, 2024
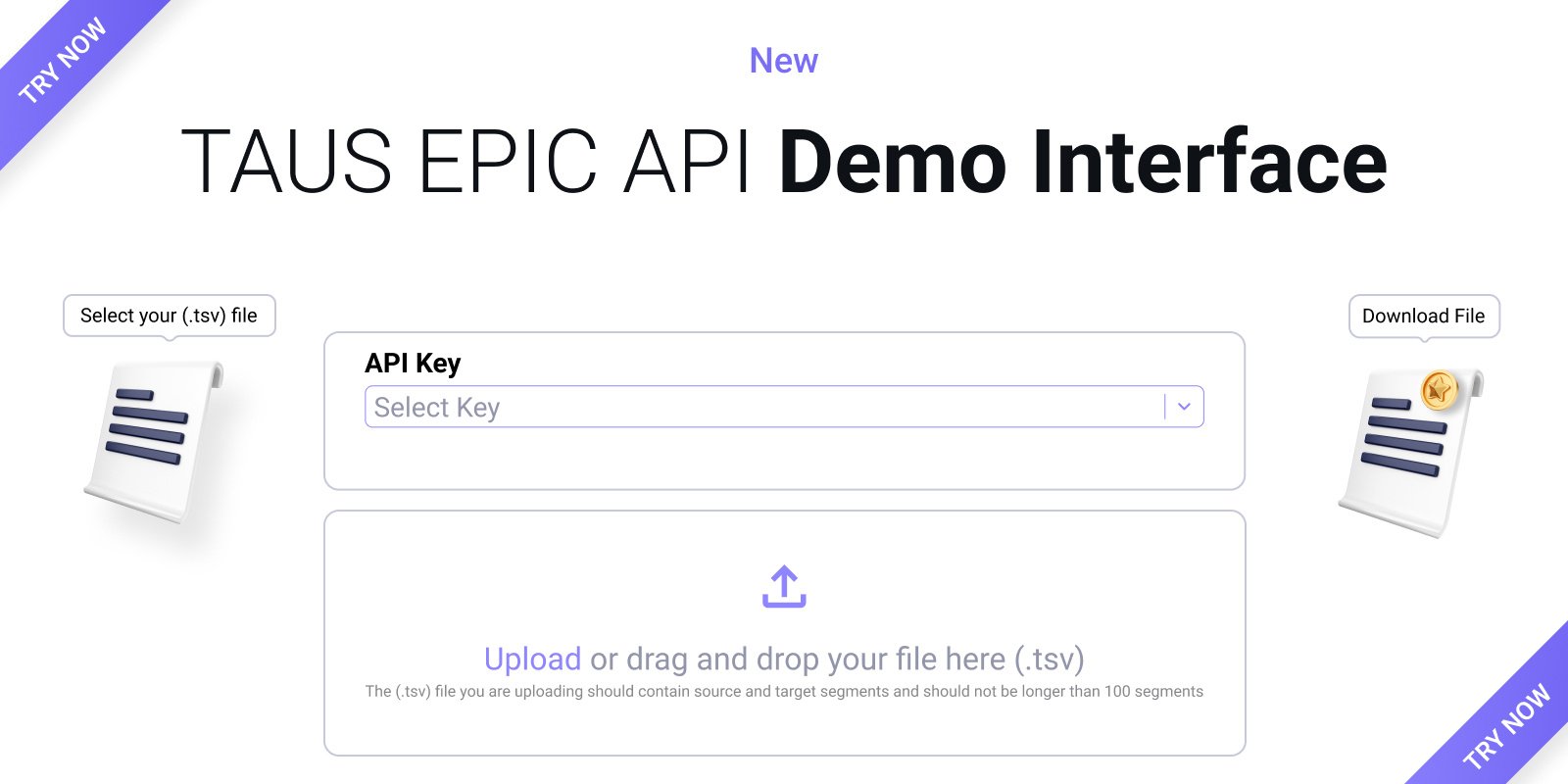
Discover the new TAUS EPIC API Demo Interface to quickly assess machine translation quality, saving time and costs while boosting productivity.
Aug 08, 2024

Discover the enhanced TAUS EPIC API V2 for improved translation accuracy in 5 EU languages, reducing post-editing efforts by up to 60%.
Jul 29, 2024